
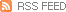
【파이썬 응용】 파이썬 웹 크롤링#2(Web Crawling) -검색결과를 csv파일로 저장하기
크롤링이란, 인터넷에서 특정검색(어)로 검색하여 (자료를) 긁어(스크랩) 모우는 행위를 일컫는다. 이를 파이썬코드나 시스템을 이용해서 반자동으로 긁어 모으로 과정을 일컫는다.
이 번 내용에서는 웹 검색 결과를 스크래핑하여 쉼표 단위로 저장이 되는 csv 형태로 저장하고자 한다.
csv 형태로 저장하는 이유는 메모장에서도 열수 있고, 엑셀에서 군더더기 없이 셀(cell)별로 읽어 들여, 이후의 가공이나 편집이 용이하기 때문이다.
이번에는 지난시간과 달리 검색되는 내용을 전체페이지 모두 긁어 저장하려 하는데, PC버전 네이버로 검색하지 않고 모바일 버전인 네이버 M 버전으로 PC에서 검색하는 형태로 코딩을 구성하려 한다.
왜냐하면 모바일 M 네이버의 (VIEW 메뉴 클릭) 하면, 검색 결과를 10개씩 페이지 별로 나타 내지 않고, 한 페이지에 모든 검색 결과를 담아 보여주기 때문인데, 스크롤 내리는 족족 검색되는 결과를 보여주기 때문에, 페이지 단위별 스크래핑을 고려 할 필요가 없기 때문이다.

PC에서 모바일 버전 네이버 검색을 해보려면 m.naver.com 으로 접속을 하면 되며,
검색창에 '파이썬' 검색을 입력하고 검색한 후 메뉴에서 View 를 클릭해서 보면,
검색결과가 계속 내려도 한 페이지에 모두 표시 되도록 스크롤이 계속 내려가는 것을 알 수 있다.
그럼 이제 코딩을 해보자.
먼저, 크롤링이 처음 이라면, 선수학습 자료를 먼저 살펴보기 바란다.
[선수학습]
2020/01/01 - [Language/파이썬 Python] - 【파이썬 응용】파이썬 웹 크롤링(Web Crawling)
# 먼저 네이버 모바일(M) 페이지에서 F12키를 눌러 웹 분석도구로 아래와(api_tx....) 같은 주요 특징(타이틀 제목 인근의 HTML 문법)을 파악해 낸다.
# api_txt_lines dsc_txt
1. 기본 검색 코드
~~~~~~~~~~~~~~~~~~~~~~
import csv
from urllib.request import urlopen
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
search = input('검색어를 입력하세요? :')
# 아래와 같이 하면 search 부분에 입력문자를 직접 대응시킬 수 있다.
# url = f'https://m.search.naver.com/search.naver?where=m_view&sm=mtb_jum&query={search}'
# 하지만, search 부분에는 입력된 한글이 웹에 사용하는 형식으로 인코딩 된 된 문자가 들어가야 한다. (quote_... 사용)
url = f'https://m.search.naver.com/search.naver?where=m_view&sm=mtb_jum&query={quote_plus(search)}'
html = urlopen(url).read()
soup = BeautifulSoup(html, 'html.parser')
total = soup.select('.api_txt_lines.total_tit') # 내용이 두 개임, 공백을 없애고 점을 찍어 붙여준다
print(total[0])
~~~~~~~~~~~~~~~~~~
여기까지의 '자바'라는 검색어를 넣어 결과를 출력해보면 아래와 같다.

2. 이제 반복문(for)을 넣어 검색결과를 모두 출력해보자.
~~~~~~~~~~~~~~~~~~~~~~
import csv
from urllib.request import urlopen
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
search = input('검색어를 입력하세요? :')
# 아래와 같이 하면 search 부분에 입력문자를 직접 대응시킬 수 있다.
# url = f'https://m.search.naver.com/search.naver?where=m_view&sm=mtb_jum&query={search}'
# 하지만, search 부분에는 입력된 한글이 웹에 사용하는 형식으로 인코딩 된 된 문자가 들어가야 한다. (quote_... 사용)
url = f'https://m.search.naver.com/search.naver?where=m_view&sm=mtb_jum&query={quote_plus(search)}'
html = urlopen(url).read()
soup = BeautifulSoup(html, 'html.parser')
total = soup.select('.api_txt_lines.total_tit') # 내용이 두 개임, 공백을 없애고 점을 찍어 붙여준다
for i in total:
print(i.text)
print(i.attrs['href'])
print()
~~~~~~~~~~~~~~~~~~
출력결과 :
3. 이제 여기에
~~~~~~~~~~~~~~~~~~~~~
import csv
from urllib.request import urlopen
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
# api_txt_lines dsc_txt // 클래스가 두 개임. 따라서 아래 부분에 공백을 없애고 점을 찍어 붙여준다
search = input('검색어를 입력하세요? :')
# 아래와 같이 하면 search 부분에 입력문자를 직접 대응시킬 수 있다.
# url = f'https://m.search.naver.com/search.naver?where=m_view&sm=mtb_jum&query={search}'
# 하지만, search 부분에는 입력된 한글이 웹에 사용하는 형식으로 인코딩 된 된 문자가 들어가야 한다. (quote_... 사용)
url = f'https://m.search.naver.com/search.naver?where=m_view&sm=mtb_jum&query={quote_plus(search)}'
html = urlopen(url).read()
soup = BeautifulSoup(html, 'html.parser')
total = soup.select('.api_txt_lines.total_tit')
searchList = []
for i in total:
temp = []
temp.append(i.text) # 텍스트 부분만 추출하여 저장(추가)함
temp.append(i.attrs['href']) # href '주소' 부분만 추출하여 저장(추가)함
searchList.append(temp)
# newline=''는 첫번째 데이터다음 한줄 내려주는 역할이다.
# 한글 때문에 utf-8로 엔코딩한다.
f = open(f'{search}.csv', 'w', encoding='utf-8', newline='')
csvWriter = csv.writer(f)
# 반복문을 만들어 csv 파일에 하나씩 데이터를 추가(기록)해준다.
for i in searchList:
csvWriter.writerow(i)
f.close()
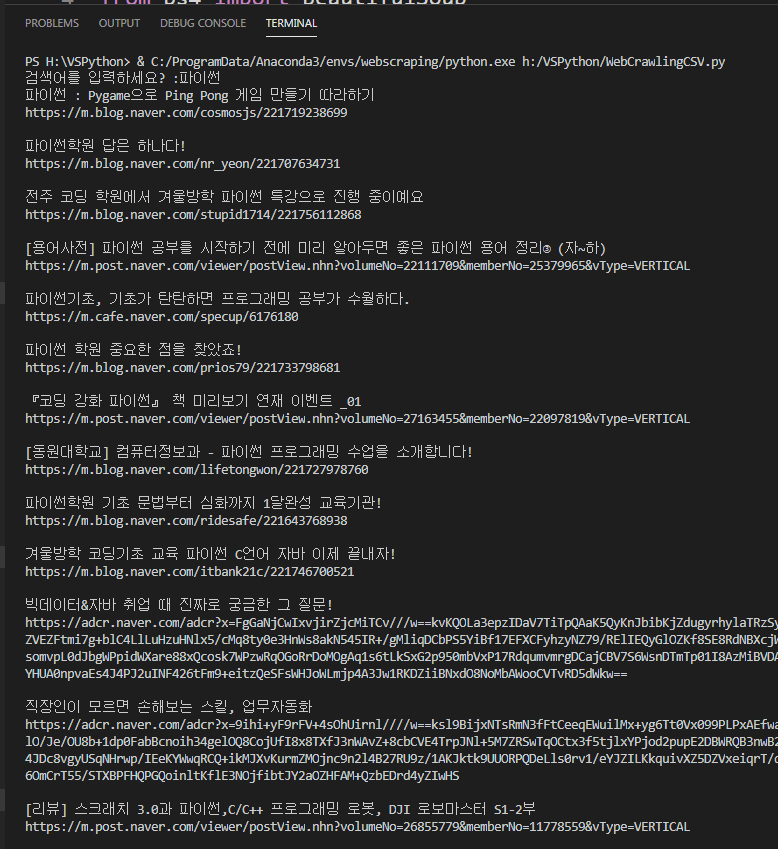
출력 결과 :
아래와 같은 형태의 파일이 저장 되었다.

이 파일을 엑셀과 같은 프로그램으로 열어 보면 저장이 되어 있다. 다만, 아래 처럼 깨져 열리게 된다.
이럴때는 리브레 오피스 같은 걸로 열 경우(유니코드UTF-8) 형식으로 옵션을 맞추어 열면 한글이 깨지지 않게 열린다.
만약 MS엑셀 같은 걸로 열경우는 열기전에 Utf-8로 미리 설정하는 옵션이 없기 때문에,
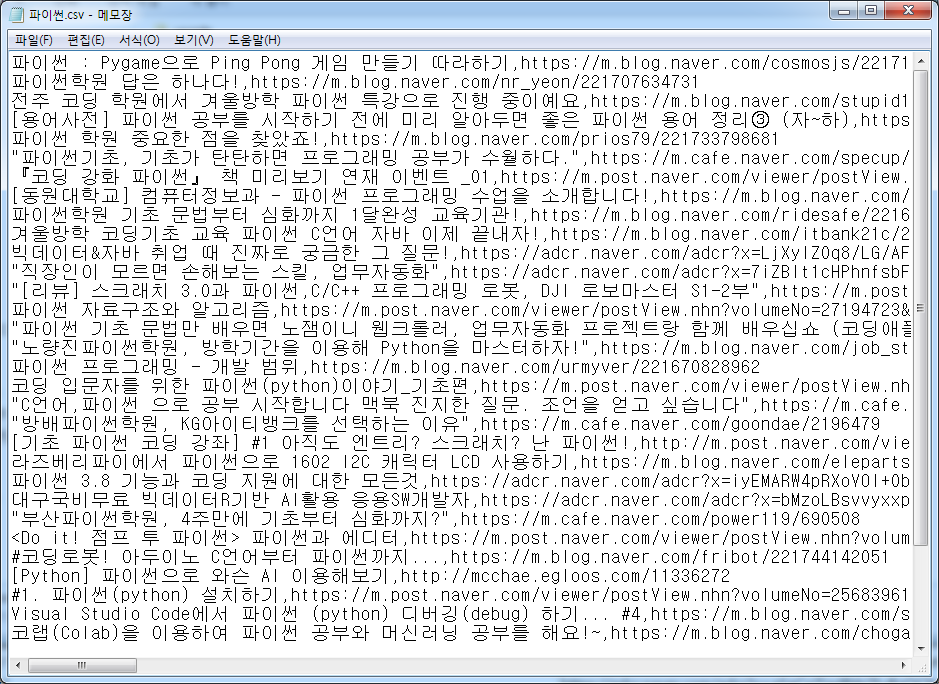
파이썬.csv 파일을 메모장으로 열고 메모장에서 열면 아래처럼 한글이 깨지지 않게 열리고,
이를 다른이름(파이썬1.csv)으로 저장할 때 '인코딩(E)' 옵션 부분을 눌러 ANSI로 저장한다.
그런 다음 MS엑셀에서 열면 맨 아래 그림처럼 한글이 깨지지 않게 잘 열리게 된다.

※ 컴파일 과정에서 에러가 난다면, url 부분에 공백이 들어가면 안 되니 확인해보면 된다.
여기에서 일반 PC용 네이버 페이지를 이용하지 않고, M.naver 페이지의 View 메뉴를 이용한 이유는 검색어로 검색했을 때 페이지 단위로 검색이 되면 그 한 페이지(약 10개) 정도의 내용만 페이지 별로 분류가 되기 때문에 좀더 복잡한 코드(방법)을 사용해야 하기 때문이다.
파이썬, 코드 다운로드 :
'Language > 파이썬 Python' 카테고리의 다른 글
| 【파이썬 에러해결 #1】 vscode 사용시 unresolved import 'pyautogui'Python warning 해결방법 (0) | 2020.01.02 |
|---|---|
| 【파이썬 응용】 파이썬 웹 크롤링#3 (Web Crawling) - 원하는 페이지 수 만큼 검색하여 저장하기 (0) | 2020.01.02 |
| 【파이썬 응용】파이썬 웹 크롤링#1 (Web Crawling) (2) | 2020.01.01 |
| 【 주피터 노트북 】 Jupyter notebook 시작시 "환경설정" (로딩 딜레이 문제 해결) (2) | 2019.12.14 |
| [ 파이썬 다운로드 ] Ver. 3.8 정식 릴리즈 버전 다운로드 및 설치 (4) | 2019.10.15 |
