1. 《 딕셔너리 란? 》 : 딕셔너리란? 파이썬에서 리스트와 함께 가장 많이 사용되는 데이터 스트럭쳐 중 하나입니다. 딕셔너리는 key 와 value 를 사용하여 데이터를 저장합니다. 그리고 python3.6 이하에서는 스트링, 리스트, 튜플, 등과는 다르게 순서가 없는 데이터 타입(data type)으로 정의했으나, python3.7 이상에서는 순서가 있도록 업데이트 되었습니다. 딕셔너리는 컬리브레이스 ( 중괄호 { } )를 사용하여 정의합니다. 아래, 내용이 비어있는 딕셔너리를 선언하고 클래스 타입을 확인해 볼게요.
2. 《 딕셔너리 사용 형식 》 : 딕셔너리의 형식은 name = { key1 : value1 , key2 : value2 , key3 : value3 ... } 처럼 key 값과 value값이 1:1로 매칭되는 형식의 데이터들을 갖습니다. 딕셔너리는 리스트나 튜플처럼 순차적으로 해당 요솟값을 구하지 않고 Key를 이용해 Value를 얻습니다. 이것이 딕셔너리의 큰 특징입니다.
예시 1) 아래 이미지처럼, Key 와 Value 한 세의 데이터 구조로 입력되며, Value 값은 Key값을 이용해 호출하거나 처리할 수 있습니다.
예시 2) 아래 이미지처럼, 하나의 연관성 있는 데이터의 모음 형태로도 사용할 수 있습니다. 그리고, name1, name2, phone1, phone2, ... 와 같은 형식으로 연속적인 데이터를 구성할 수 있습니다.
3. 《 딕셔너리 데이터 쌍(Pair) 추가, 삭제하기 》 : 딕셔너리 쌍을 추가하는 방법과 삭제하는 방법을 알아 볼게요.
우선, 아래와 같은 과자(snack)와 가격에 대한 것을 예시로 들어 볼게요.
▶ 요소 추가하기 예시) 아래 이미지에서, 과자 요소 하나를 추가할 때 사용하는 방법입니다. 딕셔너리 이름['Key']='Value'
▶ 요소 삭제하기예시) 아래 이미지에서, 과자 요소 하나를 삭제할 때 사용하는 방법입니다. del 딕셔너리 이름['Key']
▶ 요소 수정하기 예시) 아래 이미지에서, 과자 요소 중, 값(Value)을 수정할 때 사용하는 방법입니다. 딕셔너리 이름['Key'] = 'Value'
4. 《 딕셔너리의 특징(성격) 》 : 리스트의 경우 내용이 같아도 순서가 다를 경우 서로 다른 리스트로 인식됩니다. 하지만, 딕셔너리의 경우 키(Key)와 값(Value)인 요소만 같으면 순서가 달라도 같은 딕셔너리로 인식합니다. 즉, 들어 있는 순서는 중요하지 않고 관심도 없기 때문에 딕셔너리에 저장된 내용(Key와 Value)의 수와 종류만 같다면 같은 딕셔너리로 인식합니다. 따라서, 저장 순서가 중요한(필요한) 데이터가 있다면 딕셔너리에 담지 말아야 합니다.
1. 리스트 예시(리스트는 내용과 순서가 같아야 동일한 리스트로 인식)2. 딕셔너리 예시(딕셔너리는 내용만 같으면 들어있는 순서가 달라도 동일한 딕셔너리로 인식)
5. 《 딕셔너리의 in 연산과 not in 연산 》 : 딕셔너리 내용에 특정 키(Key)가 있는지 확인할 때, in 연산을 사용합니다. 딕셔너리로 데이터의 종류별로 묶어 놓을 수 있는데요, 예를 들어, 상품과 가격정보를 과자류와 음료류로 묶어 놓았을 때, 과자류의 상품정보를 수정하려다 음료류의 상품정보를 수정해버리는 실수를 가정할 수 있는데요, 이럴 때, 해당 키값이 요소에 있는지 확인을 먼저하고 진행하는 것이 필요할 수 있습니다.
예시 1) 아래는 딕셔너리 이름 지정이 잘못되어, 값 수정을 못하고 요소가 추가된 모습입니다.
딕셔너리 이름 지정이 잘못되어, 값 수정을 못하고 요소가 추가된 모습
예시 2) 따라서 아래와 같이 코딩을 할 때, 해당 딕셔너리에 요소가 있는지 , 확인하기 위해 in 연산자를 사용합니다. 그리고, if 연산자를 활용하여 쉽게 처리할 수 있습니다.
in 연산자와 if문을 활용하면, 잘못된 딕셔너리에 요소 추가 되는 것을 방지할 수 있습니다
예시 3) 반대로 아래처럼, not in 연산자를 사용하여, 해당 키값이 있는지 확인하여 없을 경우에 추가해 줄 수도 있습니다.
not in 연산자를 사용하면, 해당 요소의 중복여부를 확인하여 추가할 수 있습니다
주의해야 할 것은, 딕셔너리에서 in과 not in 연산자에서 확인하는 대상은 키(Key) 이지, 값(Value)이 아니라는 점 기억하세요.
6. 《 딕셔너리의 for 루프 》 : 딕셔너리의 Key를 대상으로 for 루프가 가능합니다. (단, Value 값으로는 대상을 돌릴 수는 없습니다)
예시 1) 음료 데이터 딕셔너리의 키 목록을 for루프로 출력해 볼 수 있습니다.
딕셔너리에서 키값으로 for문을 돌리는 경우 예시입니다.
딕셔너리에서 for문을 사용할 수 있는 것이 중요한 이유는 , 데이터 요소가 아주 많을 경우 수정이 필요할 때 for문을 돌릴 수 있는 것이 중요합니다. 예를 들어 음료 요소로 구성된 딕셔너리에서 가격 변동이 발생하여, 각각의 가격을 올리거나 내려야 할 경우, 한 번에 쉽게 적용시킬 수 있기 때문입니다. 예시 2) 아래 예시는 처음, 음료 가격에 20원씩 일률적으로 상승 시킬 경우 예시이며, 이어서 상품가격에 10%의 할인을 적용할 경우 가격 수정에 대한 예시를 들었습니다.
일률적으로 딕셔너리 Value 값을 20원씩 올리려 하는 경우와 , 10%의 할인 가격으로 조정하는 경우의 예시 입니다
【파이썬 에로해결#2】 윈도에서 파이썬 IDLE가 갑자기 실행되지 않을 때! (When Python IDLE suddenly does not run on Windows! )
1. 《 문제증상-Problem 》 : 윈도에 설치한 윈도버전 Python 3.xx 를 설치하고 잘 사용하다보면 갑자기 Windows IDLE 64bit가 실행이 되지 않는 경우가 발생합니다. 물론 Python 3.x IDLE를 제외한 다른 프로그램은 실행이 잘되지만, IDLE (Python 3.9 64-bit) 버전만 실행이 되지 않습니다.
아래처럼, Shell 형태의 Python 3.9는 실행이 잘 됩니다.
하지만, Python IDLE는 실행을 시켜보면 아무 반응이 없습니다. 관리자 권한으로 실행을 해봐도 무반응입니다. Other programs except Python 3.x IDLE run fine, but only IDLE (Python 3.9 64-bit) version does not run.
이런 증상이 있을 때, 해결하는 방법은 아래와 같습니다. Let me show you how to fix it.
2. 《 해결방법-Resolution 》 : 파이썬 프로그램이 설치되거나, 혹은 업그레이드 버전이 설치되면, 사용자 정의 글꼴 및 크기, 사용자 정의 키 바인딩 및 기타 정보들을 기록하는 폴더가 있습니다. 이 폴더의 내용이 엉키거나 할 경우 파이썬 IDLE가 실행이 되지 않는 것으로 보이는데요, 그래서 해결방법은, 이 폴더 안에 있는 내용(기록 파일)을 모두 지우면 됩니다. 지우고 Python IDLE를 실행하면, 다시 시로운 정보 파일을 만들면서 실행이 됩니다. 해당 폴더의 위치는 아래와 같습니다.
%USERPROFILE%\.idlerc
윈도 탐색창에 위의 경로를 복사하여 탐색창 주소 부분에 붙여 넣기 하면, USERPROFILE 부분에는 자동으로 자신의 윈도 사용자명으로 바뀌고 파이썬의 해당 폴더로 이동하게 됩니다. ( ₩는 경로 표시의 역슬래시\입니다) 아래처럼, 윈도 탐색창의 주소부분에 위의 경로를 복사 붙여 넣기 하세요.
아래가 문제가 생겼을 때의 위 폴더 위치로 이동해본모습입니다. 그럼, 기존 설정 파일이 보일 거예요.
그럼 폴더 속에 있는 파일들을 모두 선택해서 아래처럼 삭제해주세요.
그리고 다시 Python IDLE를 실행시켜 보면, 아래와 같이 새로운 설정 파일을 하나 생성하면서, IDLE가 다시 실행되는 것을 볼 수 있습니다.
1. 《 사용자 정의 모듈 만들기 》 : 활용 빈도가 높은 내용을 사용자 정의 함수 형태의 파일(.py)로 만들어 다른 파이썬 코드에서도 쓸 수 있게 만든 것을 말합니다. 마치 C언어에서 "xxx.h" 헤더 파일을 활용하는 형태와 유사합니다. 일반적인 사용자 정의 함수는 하나의 파일 내에서 서브루틴 형태로만 사용되지만, 헤더 파일 활용하듯 별도의 파이썬 파일로 만들어 사용하는 것을 말하며, 이를 파이썬에서는 보통 모듈이라고 합니다. 이런 모듈은 다른 사용자에게 줘서 활용할 수도 있는데, 대표적으로 수학 관련 모듈이나, 데이터 관련 모듈이 이에 해당됩니다.
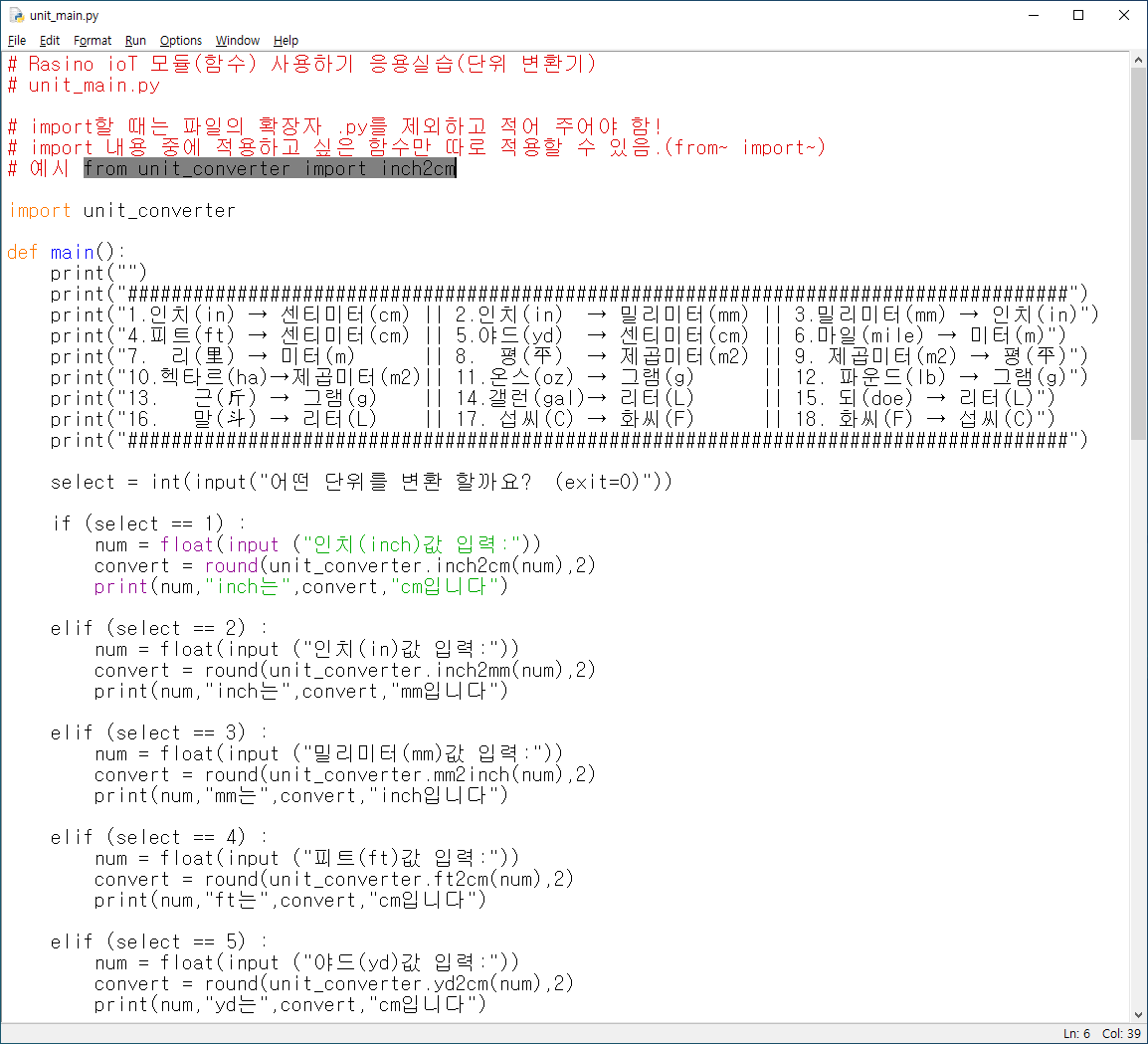
그럼, 아주 간단한 예시로, 아래처럼, 인치(inch)를 입력하면 mm(밀리미터) 혹은, cm(센티미터)로 바꾸어 주는 함수를 만들어 보겠습니다.
사용자 정의 함수로 인치를 밀리미터로 바꾸어주는 함수 inch2mm( )와 인치를 센티미터로 바꾸어 주는 함수 inch2cm( )를 만들어 정의하였고 , 2인치(inch)라는 수와 3인치라는 수를 각각 넣은 결과를 보여 주고 있습니다. 그럼, 인치를 밀리미터로 변환하는 파일(inch2mm.py)을 만들어 main( ) 함수 파일에서 모듈로서 import 하여 사용하고, 마찬가지로, 인치를 센티미터로 변환하는 파일(inch2cm.py)을 만들어 main( ) 함수 파일에서 모듈로서 import 하여 사용해보는 코드를 작성해 볼게요. main ( ) 코드의 파일 이름은, "inch2mm_cm.py"로 하겠습니다.
1. 먼저, 인치를 밀리미터로 변환하는 파일(inch2mm.py) 입니다.
2. 다음, 인치를 센티미터로 변환하는 파일(inch2cm.py) 입니다.
3. 그럼, 메인 파일(inch2mm_cm.py) 입니다.
# Rasino ioT 모듈(함수) 사용하기 실습
# inch2mm_cm.py
# import할 때는 파일의 확장자 .py를 제외하고 적어 주어야 함!
import inch2mm # 인치를 mm로 변환하는 모듈(파일.py) 사용 선언
import inch2cm # 인치를 cm로 변환하는 모듈(파일.py) 사용 선언
def main():
inch_num = float(input ("인치(inch)값 입력:"))
inch_mm = round(inch2mm.inch2mm(inch_num),2)
inch_cm = round(inch2cm.inch2cm(inch_num),2)
print("입력 값",inch_num,"은 ",inch_mm,"mm이며, 또는",inch_cm,"cm입니다")
main()
4. 메인파일(inch2mm_cm.py)에서 실행시켜 결과 확인하기.
보이는 것처럼, 인치값으로 3을 입력했을 때, mm 변환 값과, cm 변환 값이 출력되었고, 다른 인치값 2를 입력했을 때도, 잘 출력된 것을 볼 수 있습니다. 처음 3인치를 입력했을 때, 딱 떨어지지 않은 아주 긴 소수점 값으로 나오기에, 소수 2자리까지로 제한하기 위해 round( ) 함수를 사용했습니다.
주의해야 하는 사항은, 위에서 작성한 3개의 파일 모두 하나의 같은 폴더에 있어야 합니다. import를 선언할 때는 파일의 확장자 .py를 제외하고 적어 주어야 합니다! 그리고, 모듈(파일)을 가져다(import) 쓸 때는, 적용하고 싶은 함수만 가져다(import) 쓸 수 있습니다. (예시, from unit_converter import inch2cm )
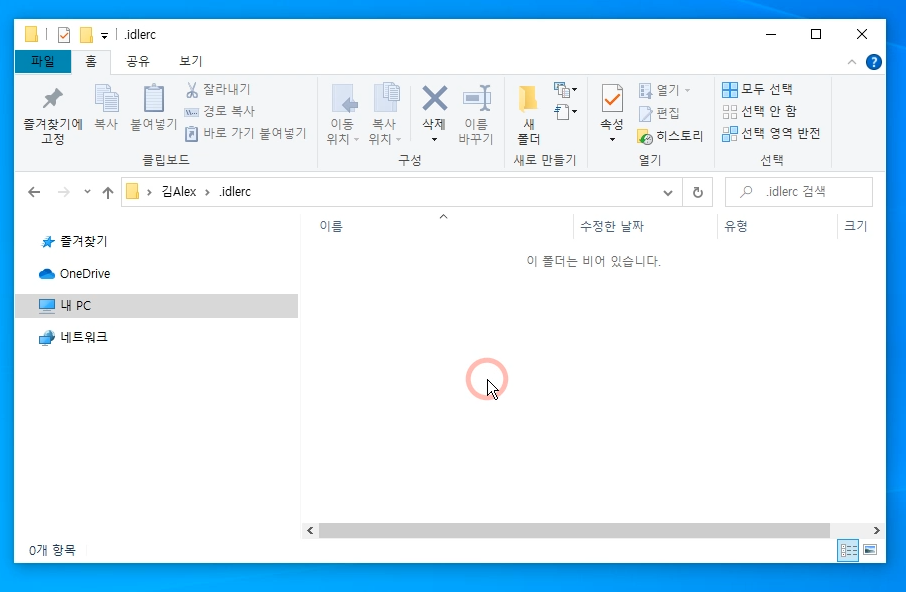
그럼, 단위 변환을 주제로, 사용자 정의 모듈을 만들어 활용해보는 예제를 만들어 볼게요. 실제 단위 변환에 종종 사용될 수 있는 항목으로 18개를 준비하였으니, 활용해 보세요. 1. 단위 변환 18종 파일(unit_converter.py)
1. 모듈을 가져다 쓸 때 위의 예시처럼, 모듈 파일 전체를 포함(import) 시키는 방법이 있습니다. → import unit_converter (unit_converter.py 모듈 파일 전체를 포함(가져다) 쓰겠다) 2. 모듈 파일 속에 필요한 함수만 골라서 포함(import)시켜 사용할 수 있습니다. → from unit_converter import inch2cm (unit_converter.py 모듈 속의 '인치를 cm'로 변환하는 함수만 사용) → from unit_converter import ft2cm (unit_converter 모듈 속의 '피트ft를 cm'로 변환하는 함수만 사용) 또는 한 줄로 선언할 수도 있습니다. → from unit_converter import inch2cm, ft2cm (unit_converter 모듈 속의 inch2cm와 ft2cm을 가져다 쓰겠다)
하지만, 이렇게 할 경우, 원래의 함수 이름(inch2cm)과 가져다 쓰려고 선언한 이름(inch2cm)이 같아서 컴파일하면 오류가 생기게 되는데요, 그래서, 가져다 쓰려고 선언하는 이름을 'as' 단어를 붙여서 선언하게 됩니다. (아래) → from unit_converter import inch2cm as i2c (unit_converter.py 모듈 속의 '인치를 cm'로 변환하는 함수를 i2c라는 이름으로 사용하겠다) → from unit_converter import ft2cm as f2m (unit_converter 모듈 속의 '피트ft를 cm'로 변환하는 함수를 f2m라는 이름으로 사용하겠다) 이렇게 as를 사용하면, 선언할 모듈(함수)의 이름이 길 경우 줄여서 사용할 수 있는 장점도 있습니다.
unit_converter.py 함수 중에서, 필요한 몇 가지 함수만 as라는 이름으로 바꾸어 사용한 코드
unit_converter.py 함수 중에서, 필요한 몇 가지 함수만 as라는 이름으로 바꾸어 사용한 코드입니다.
아래는 위 코드의 실행 결과입니다.
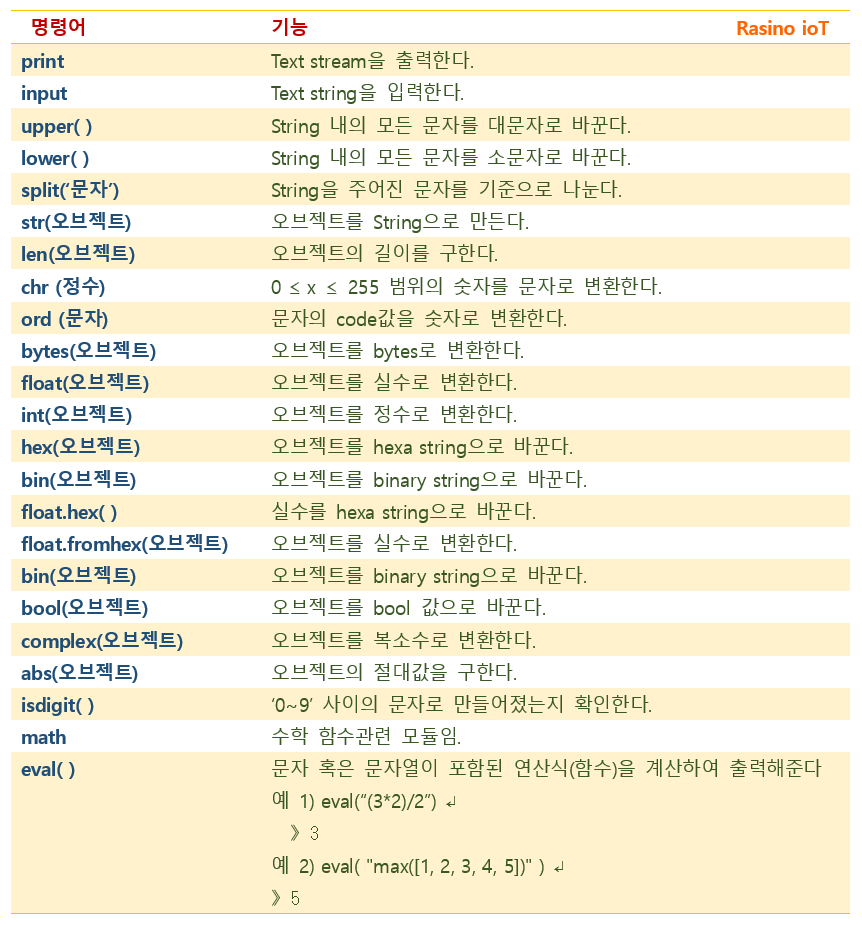
2. 《 빌트인 모듈(built-in module) 》 : 빌트인 가전제품처럼, 파이썬에도 빌트인 모듈(함수)라는 것이 있는데, 파이썬을 설치하게 되면 바로 활용할 수 있는 모듈을 말합니다. 예를 들면, print, input, abs, eval, chr 등이 있습니다. 따라서 빌트인 함수들은 별다른 정의 없이 기존 정의된 대로 사용할 수 있게 되며, 파이썬 shell 프롬프트에서 아래처럼 print( 형태로 입력 후 나타나는 주석을 참고할 수 있습니다.
그리고, (아래) 매개변수 값 입력 없이, print , input 등으로 입력해보면, 해당 함수는 built-in 함수라는 것을 알려줍니다.
이와 같은 기본 빌트인 함수들에는 아래와 같은 것이 있습니다.
파이썬 내장 함수들 ( Built-in Functions )
abs( )
dict( )
help( )
min( )
setattr( )
all( )
dir( )
hex( )
next( )
slice( )
any( )
divmod( )
id( )
object( )
sorted( )
ascii( )
enumerate( )
input( )
oct( )
staticmethod( )
bin( )
eval( )
int( )
open( )
str( )
bool( )
exec( )
isinstance( )
ord( )
sum( )
bytearray( )
filter( )
issubclass( )
pow( )
super( )
bytes( )
float( )
iter( )
print( )
tuple( )
callable( )
format( )
len( )
property( )
type( )
chr( )
frozenset( )
list( )
range( )
vars( )
classmethod( )
getattr( )
locals( )
repr( )
zip( )
compile( )
globals( )
map( )
reversed( )
__import__( )
complex( )
hasattr( )
max( )
round( )
delattr( )
hash( )
memoryview( )
set( )
(Rasino ioT)
그 외에, 루트 값, 절대 값, 싸인, 코싸인, 파이값 등 수학 관련 함수들을 따로 모아 놓은 math라는 모듈 함수가 있는데요, 40개 이상의 함수가 들어 있으며, 간단히 import math라고 선언만 해주면, 사용할 수 있습니다.
1. 《 if 문 》 : 조건이 맞으면 실행을 하라~! "if 조건 : " 문은 if 뒤에 조건이 맞으면(true) if 문에 속해 있는 문장들을 실행하게 됩니다.
파이썬에서는 C언어에서 처럼, if문에서 { 중괄호 } 같은 것을 사용하지 않고, 인터프리터 언어의 특성인 한 줄씩 처리되도록 하기 위해 ' : ' 콜론을 사용합니다. 그렇기 때문에, if문에 속해 있는 문장들은 모두 들여 쓰기(탭키, 혹은 보통 4칸)를 하여 구분합니다. 또한, 파이썬은 유연성이 좋아 위 예시처럼 한 줄에 출력까지 기술해 줄 수 있습니다.
2. 《 if ~ else 문 》 : 조건이 참(True)이면 실행할 코드와, 조건이 거짓(False)이면 실행할 코드를 구분하여 작성할 때, 사용하게 됩니다.
if <조건> : (조건이 True 참이면 실행할 문장들 ... ) else : (조건이 False 거짓이면 실행할 문장들 ... )
- def '함수명( )' 은 사용자 정의 함수입니다. - num = int (input(" 입력....: ")) >> 화면에 숫자를 입력받을 때, 글자를 출력하고, 입력받은 숫자(문자)를 정수형으로 처리하여 num이라는 변수에 대입하는 형태를 많이 사용합니다.
3. 《 if ~ elif ~ else 문 》 : 조건이 여러개인 상황에서 하나를 선택하도록 할 때 사용하게 되는 코드 유형입니다.
if <조건 1> : (조건 1이 True 참이면 실행할 문장들... ) elif <조건 2> : (조건 2가 True 참이면 실행할 문장들... )
elif ...
else : (위의 모든 조건이 False 거짓이면 실행할 문장들... )
< 아래 예제 코드를 참고하세요 >
※ if 문의 기본 구조는 , if 《 조건 》입니다. 그래서 조건이 참(True)이면, if : 문에 속해 있는 내용들이 실행되며, 조건이 거짓(False) 이면, 실행되지 않습니다. 그럼 여기서, 조건의 기준인 True와 False 가 되는 기준이 있다는 것을 알 수 있습니다. Bool 값인 'False'와 숫자 '0' 그리고 ' ' 공백은 False로 처리되며, 이것 이외의 모든 것 들은 True로 처리됩니다. 예를 들어, 논리 값 'True' , 숫자 '1' 뿐 아니라, '2', '3', ... , 영문자 'A' , 'a', 'b', 등등 모두 True로 처리되어, if 문에 속한 코드들이 실행됩니다.
3. 《 if 문과 논리 연산자 》 : if 문에서 하나 이상의 조건을 비교해야 할 때, 논리 연산자를 사용하여 처리할 수 있습니다. 아래가 사용할 수 있는 논리 연산자입니다.
연산자
설명
예시
and
두 조건이 모두 참인 경우 성립되는 연산자.
if a == 1 and b== 2 : print("OK")
: a가 1이고, b가 2 모두를 만족할 때 print문이 실행됩니다
or
두 조건 중 하나라도 참이면 성립되는 연산자.
if a == 1 or b== 2 : print("OK")
: a가 1이거나, 또는 b가 2라면, 둘 중 하나만 만족한다면 print문이 실행됩니다
not
조건을 반대로 뒤집는 연산자.
if not a == 1 : print("OK")
: a가 1이 아니라면, print문이 실행됩니다
물론, 위의 연산자 여러 개를 조합하여 사용 가능합니다. 그 밖에, 아래 비교 연산자를 활용할 수 있습니다.
연산자
설명
==
같다
!=
다르다 (같지 않다)
<
좌변이 우변보다 작다
>
좌변이 우변보다 크다
<=
좌변이 우변보다 작거나 같다
>=
좌변이 우변보다 크거나 같다
4. 《 in과 not in 연산자 》 : 리스트 혹은 문자열에 해당 문자(숫자)가 있는지? 확인하여 참(True) 또는 거짓(False)으로 반환합니다. in과 not in 연산자는 뒤에 for 문과 if문에도 사용되니 기억해 두세요. 1. x in str : str에 x가 있으면 True, 없으면 False를 반환 2. x not in str : str에 x가 없으면 True, 있으면 False를 반환
5. 《 for 루프 》 : for 루프 문의 기본 골격은 아래와 같습니다. for《변수》in《범위》 : <for에 속하는 문장들...> <for에 속하는 문장들...>
<예시>
또는 위에 범위에 해당되는 부분을 range( )로 표시하여 아래처럼 줄여 표현할 수 있습니다.
6. 《 while 루프 》 : while 루프문의 기본 골격은 아래와 같습니다. while 《 조건 》 : <조건이 True인 경우 동안 계속 반복 실행될 코드들...> <조건이 True인 경우 동안 계속 반복 실행될 코드들...>
<예시>
7. 《 break 》 : while 루프 문이나, for 루프문에서 사용할 수 있으며, break가 실행되면, 해당 루프 문을 종료하고 빠져나오게 됩니다.
<예시>
8. 《 continue 》 : while 루프문이나, for 루프문에서 사용할 수 있으며, while문이나, for 루프문 속에서 continue 문장을 만나면, continue 문 아래 문장들은 실행되지 않으며, while문이나 for문의 다음 반복으로 계속 이어집니다.
9. 《 for문 이중 루프 》 : for 루프문을 이중으로 이용할 수 있으며, 이중으로 반복해야 하는 곳에 사용하게 됩니다. 아래, 구구단을 예시로 들겠습니다. < 파이썬 구구단 >
>>> < 구구단 2단부터 9단까지 한 단씩 세로로 출력하기 > >>> for dan in range(2, 10): print("=====",dan,"단=====") for hang in range(1, 10): print(dan," * ", hang,"=",dan*hang) print() # 한 줄 띄움
※ 그럼, 이번에는 구구단을 가로로 한 번에 출력해 볼게요. >>> < 구구단 2단부터 9단까지 가로로 한 번에 출력하기 > >>>def gugudan() : print (" ====== 구구단 가로로 출력하기 =====") for hang in range(1, 10) : for dan in range(2, 10): print(dan,"*",hang,"=",dan*hang," | ",end="\t") print()
이미지 클릭시 확대 됩니다
위와 같이 "\t" 탭 출력을 이용해서 가로로 출력이 잘 되었습니다. 그런데, 약간의 문제는 두 자릿수 값 출력의 경우 출력 자리가 밀려서 정렬이 깔끔하게 되지 않는데요, 이때는, print문의 출력 형식을, C언어에서와 같은 형식으로 정수의 자리를 지정하여 출력하면 해결할 수 있습니다.
< 구구단, 출력 정렬하여 가로로 출력하기 > >>>def gugudan() : print (" ====== 구구단 가로로 자리 정렬하여 출력하기 =====") for hang in range(1, 10) : for dan in range(2, 10): print("%d * %d = %2d | "%(dan, hang, dan*hang), end="\t") print() >>> gugudan()
이미지 클릭시 확대 됩니다
10. 《 pass 》 : 파이썬에서는 아무 기능을 하지 않는 빈 코드의 역할로 pass 키워드를 사용합니다. 보통 C언어의 비어있는 코드의 역할로 { } 중괄호를 사용하는데, 파이썬에서는 { } 중괄호를 사용하지 않기 때문에, pass라는 키워드를 사용합니다. pass는 코드가 다소 복잡하거나 사이즈가 어느 정도 되는 코드를 작성할 때 나중에 완성할 함수 같은 부분에 pass를 넣어놓고 최소한의 구조를 완성시켜 놓고 작업하게 되는데, 이러면 나중에 완성해야 할 부분에 대한 표시도 되고, 다른 코드 부분을 테스트하기에도 방해되지 않아 편합니다.
< 예시 > score = 100 if score >= 80 : else: 이와 같이 작성한다면, 나중에 작성한다 하더라도, 우선적으로 구문 형식이 맞지 않고, 다른 부분 에러 테스트에도 이 부분 때문에 에러가 발생하여 불편을 주게 됩니다. 이럴 때, 아래처럼 우선 아무 역할도 하지 않는 pass를 넣어 작업을 진행하면 됩니다. score = 100 if score >= 80 : pass else : pass
11. 《 함수 》 : 함수는 반복적으로 처리해야 하는 부분을 함수로 만들어 놓고 호출하게 되면, 소스코드가 짧아지고, 크기도 줄어들기 때문에 많이 활용하게 됩니다. 이를 사용자 정의 함수라고 하며, def ... 형식으로 만들어 사용할 수 있습니다. 또한 이미 통상적으로 사용되는 기능들을 함수로 만들어 놓았는데, 이를 내장 함수라 칭합니다. 내장 함수이기 때문에, 별도의 import 문을 사용하여 라이브러리를 추가하지 않고 바로 사용가능합니다. < 파이썬 내장 함수 >
<문자열 검색 관련 함수들> 문자열에 내용을 검색하여 알려주는 기능의 함수 들입니다. 함수의 이름은 is xxx ( )의 조합으로 이해하면 기억하기 쉽습니다.
함수
설명
isalpha( )
모든 문자가 알파벳인지 조사합니다.
islower( )
모든 문자가 소문자인지 조사합니다.
isupper( )
모든 문자가 대문자인지 조사합니다.
isspase( )
모든 문자가 공백인지 조사합니다.
isalnum( )
모든 문자가 알파벳 또는 숫자인지 조사합니다.
isdecimal( )
모든 문자가 숫자인지 조사합니다.
isdigit( )
모든 문자가 숫자인지 조사합니다.
isnumeric( )
모든 문자가 숫자인지 조사합니다.
isidentifier( )
명칭으로 쓸 수 있는 문자로만 구성되어 있는지 조사합니다.
isprintable( )
인쇄 가능한 문자로만 구성되어 있는지 조사합니다.
위와 같은 함수는 사용자로부터 특정 값을 입력받았을 때, 입력값이 숫자로만 이루어져야 한다든지? 알파벳 소문자로만 이루어져야 한다든지? 특수문자가 있으면 안 된다든지? 등과 같은 상황에서 체크를 쉽게 할 수 있어 활용성이 좋습니다.
<예시 : 사용자 입력값에 숫자만 허용하고자 할 때>
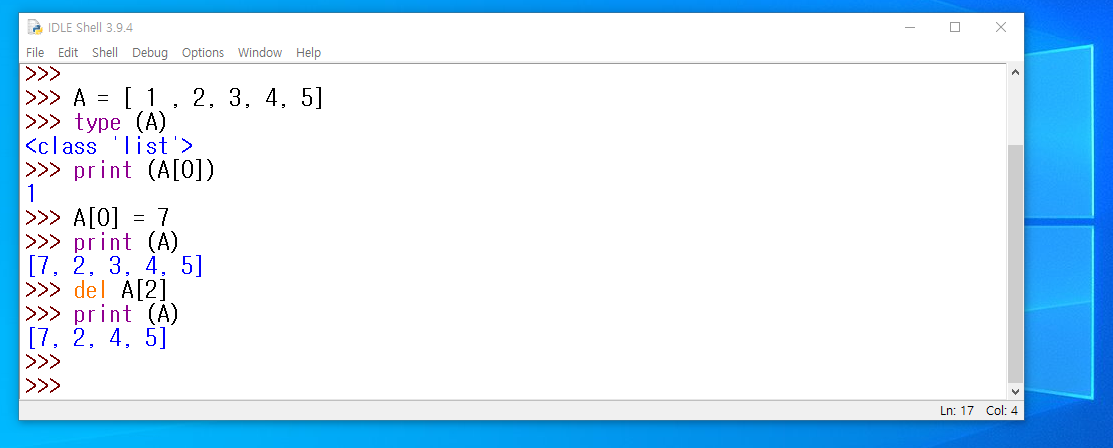
12. 《 튜플과 리스트 》 : 튜플은 리스트[list] 처럼 파이썬이 인식하는 데이터의 한 종류입니다. 리스트와 비슷한점이 있지만, 결정적인 차이가 있습니다. - 리스트와 튜플은 모두 하나 이상의 값을 묶는 용도로 사용합니다. - 리스트는 [ 1, 2, 3, ... ] 중괄호를 사용하고, 튜플은 ( 1, 2, 3, ... ) 소괄호를 사용합니다.
- 리스트는 아래 이미지처럼, 요소를 추가하거나 다른 값으로 수정이 가능합니다.
- 하지만, 튜플은 값을 참조하는 것은 가능하지만, 처음 정해진 값의 요소를 수정 변경할 수 없는 차이가 있습니다.
튜플은 기존 값에 값을 추가하거나 변경이 불가 합니다
- 이렇듯 튜플은 리스트에 비해 유연하지도 않고, 리스트형만 있어도 될 것 같지만, 분명한 쓰임새가 있습니다. - 예를 들어, 생년월일 정보나, 고유 ID 요소 등, 의도하지 않은 조작에 의해 요소값이 변경되어서는 안 되는 데이터 유형에 사용할 수 있습니다.
- 리스트관련 사용가능한 함수와 연산에 대해서는 앞선 내용에서 많이 다루었는데요, 그럼 튜플 관련 함수와 연산에 대해 살펴볼게요. 여기서 리스트 데이터형에 사용된 함수의 대부분이 튜플에도 그대로 적용되는 경우가 많습니다.
함수
설명
len(x)
튜플 x의 길이(요소의 개수) 반환
min(x)
튜플 x의 요소 중에서 가장 작은 값 반환
max(x)
튜플 x의 요소 중에서 가장 큰 값 반환
s.count(x)
튜플 s에 저장된 요소 중에서 x의 개수 반환
s.index(x)
튜플 s에 저장된 요소 중 첫 번째 x의 인덱스 값 반환
튜플의 함수 적용 예시
그리고, 튜플은 리스트와 마찬가지로 아래와 같은 연산이 가능하다.
위 연산에서 보면, Tpl + (6, 7) 연산의 결과로 기존 튜플에 요소가 추가(변경) 된 것으로 보이지만, 다시 Tpl을 출력해보면, 기존 값(1, 2, 3, 4, 5)이 그대로 있으며, 수정된 것이 아니라 새로운 튜플이 만들어 진 것입니다. 그래서 이를 Tpl2에 저장해서 보여준 것입니다. 기타 리스트에서 가능했던 * 곱하기 연산이나 [2:6] 인덱스 값 읽기 등 수정되지는 않지만 모두 동일하게 가능합니다. 그리고 아래처럼 for 루프 문에서 사용하던 문법도 동일하게 적용가능합니다.
for 문에서의 리스트와 튜플 요소 참조
단, 아래와 같은 range ( ... ) 함수는 튜플이 아니라 range( ) 라는 자체 함수를 참조 사용한 것입니다. range 함수 원형 : range( 초기값, 최종값, 증가값) - 증가값은 생략가능(1씩 증가)
그런데, range( .... ) 함수가 없다면, 예를들어, 1에서 100까지의 수를 리스트나 튜플로 참조하려면 매우 짜증?이 나겠지요? (ex, for i in [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, .... ] ) 그래서 range ( ) 함수를 사용하면 간단히 해결 되며, step 간격도 넣어 줄 수 있습니다.
- 또한 아래처럼, range( ) 함수를 이용하면, 매우 긴 연속된 수를 간단히 리스트나 튜플로 만들 수 있습니다. (예, 만약 1~100까지의 수를 리스트 변수나, 튜플 변수의 요소로 만든다고 한다면, Lst = [1, 2, 3, 4, 5.... 100??? ], Tpl = (1, 2, 3, 4, 5, ... 100???) 어휴.... 생각만해도 손목의 피로도가... )
range( )함수를 이용하면 많은 수의 요소를 직접 입력하지 않아도 된다
[ 리스트와 튜플 데이터의 상호 변환이 가능합니다! ]
아래처럼 list( ) 함수와, tuple( ) 함수를 이용하면, 리스트 데이터를 튜플데이터로, 튜플데이터를 리스트 데이터로 상호 변환이 가능합니다.
리스트와 튜플 데이터의 상호 변환
[ 문자열을 리스트와 튜플 데이터로 저장하기! ] 아래처럼, 문자열을 하나하나 떼어 리스트 데이터나 튜플 데이터로 각각 저장 가능합니다.
문자열을 리스트와 튜플 데이터로 저장하기!
[ range ( ) 함수 의 범위 거꾸러 지정하기] range 함수 원형 : range(초기값, 최종값, 증가값) - 증가값은 생략가능(1씩 증가)
range 함수의 범위를 거꾸로 넣기 위해 range (10, 1) , 또는 range(10, 1, 1) 로 해서는 안 됩니다. range 함수 원형을 보면, 생략가능한 세번째 요소가 기본적으로 증가값 이기 때문에, 초기값 10에서 1까지 증가 시킬 수는 없기 때문입니다. 만약 이렇게 하면 비어 있는 값으로 저장됩니다. 따라서, 아래 이미지 처럼, -1, 또는 -2처럼 음수 값의 감소값을 주어야 합니다.
range 함수의 범위를 거꾸로 넣기 위해서는 세번째 요소를 음수로 주어야 함
13. 《 함수 만들기 》 : 파이썬에서 함수 만들기에 대해 다루어 보겠습니다. 파이썬에서 함수를 'def' 라는 표시자를 사용하여 함수를 정의하고, 함수명 예를 들어 Hello( )을 정하고 ' : ' 콜론을 붙여서 그 아래 줄부터 함수의 내용을 넣으면 됩니다. 그리고 함수명 Hello( )를 호출 하여 사용할 수 있습니다. ⊙ 함수의 유형은 대략 아래 세가지로 분류할 수 있습니다. 1. 아무 값도 전달 받지 않는 함수 2. 값을 전달받는 함수 3. 값을 반환하는 함수 (return 명령을 갖는 함수)
먼저 1번 함수의 예시는 아래와 같습니다. <1. 아무 값도 전달 받지 않는 함수 예시>
인자의 전달이 없는 기본 함수의 유형
<2. 값을 전달 받는 함수 예시> 두 번째 함수 유형으로, 인자 값을 전달만 받고 처리하는 함수의 유형입니다. 함수를 호출 할 때, 인자값 또는 인수값이라 불리우는 영어로 argument 를 전달해 주고 , 함수에서는 이 값을 처리해서 출력하거나 하며 결과값은 되돌려 주지 않는 형태의 함수 유형입니다. 아래 예시에서는 결과값 확인을 위해 print문을 사용했으나, 보통은 처리만 하고 아무결과도 반환하지 않도록 작성할 수 있습니다.
인자값을 전달하는 함수 유형 만들기
<3. 값을 전달(반환) 받는 함수 예시> 일반적으로 인자값을 매개변수를 통해 전달받아 처리하고 'return' 명령어를 통해 결과값을 반환하는 유형의 함수입니다.
인자값을 매개변수로 받아 처리후 전달(리턴)하는 함수 만들기 유형
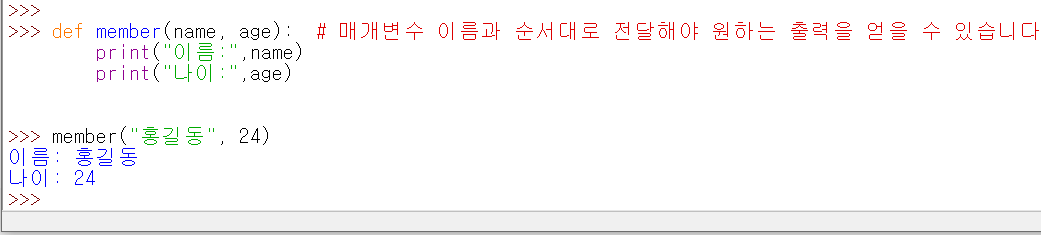
<4. 매개변수 값 이름을 지정하여 전달하기 > 함수내에서 지정한 매개 변수 이름과 순서대로 전달해야 원하는 출력을 얻을 수 있습니다.
만약, 함수에서 정의한 순서를 무시하고 바꾸면, 아래처럼, 원하지 않는 결과를 얻을 수 있습니다.
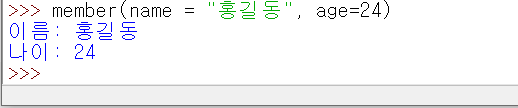
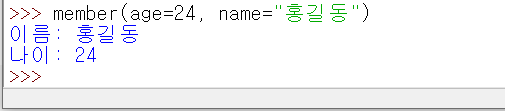
그래서, 아래 처럼, 매개변수를 직접 지정해서 전달 할 수도 있습니다.
이렇게 지정하게 되면, 매개 변수 입력 순서에 상관 없이 전달 할 수 있게 됩니다 .
print 문도 일종의 함수 이며, 사용자 정의 함수가 아닌, 내장함수 입니다. 여기에도, 매개 변수가 사용되는데요,
end 라는 매개 변수는 출력문 내용 끝에 출력을 지정할 수 있습니다. - end =' ' → print 함수의 경우 기본적으로 이렇게 단따옴표''혹은, 공백이 있는 단따옴표를 매개변수를 넣게 됩니다 - end ='' → 출력 결과는 공백이 없어도, 더 많은 공백을 넣어도 동일하게 처리 됩니다. - end =')^^(' → end 문에 특정한 문자를 넣으면 해당 문자로 마무리 됩니다. - sep ='/ ' → sep은 separator 구분자로 출력 내용 사이에 출력하여 구분시켜 줍니다. 또한, 이 둘을 같이 사용할 수 있습니다. 아래 예시들을 참고해 보세요.
<5. 매개변수에 디폴트 값 지정하기 > : 사용자 정의 함수에서 매개변수에 디폴트 값을 지정해 줄 수 있습니다. 단, 디폴트 값이 있는 매개변수 항목은 디폴트 값 없는 항목 뒤에 위치해야 합니다.
권장사항 : 기초 부분 전체를 총정리하였기에 내용이 상당히 길어 전체적으로 쭉 보시거나, 원하는 부분을 찾을 때는 'Ctrl + F' 키를 눌러 단어 검색으로 바로 이동해서 보시면 됩니다. 첨부된 이미지는 모두 직접 작업하여 첨부하였기에 이미지 클릭시 확대되어 선명하게 보실 수 있습니다.
【 파이썬 기초#5】 파이썬 기초 한방에 정리하기! #1편 , 코드 작성법 핵심 요약, 총정리!
파이썬은 스크립트 방식의 프로그래밍 언어입니다.
- 스크립트(Script) 언어의 사전적 의미는 , 연극의 대사 등이 적혀 있는 스크립트(Script)에서 유래하였으며, 연기자가 스크립트를 보고 연기를 수행하듯이 컴퓨터가 스크립트를 읽어 수행한다는 의미를 지니고 있습니다. - 또한 파이썬은 한 줄 한 줄 읽어 바로바로 실행하는 인터프리터(Interpreter) 방식을 취하고 있습니다.
그럼, 여기서 컴파일(Compile) 언어와 스크립트(Script) 방식 언어의 차이점을 설명드릴게요.
컴파일러와 인터프리터의 차이점(이미지 참조: guru99.com)
위 이미지를 보면 컴파일 언어(컴파일러)는 소스코드를 컴파일러에 의해 기계가 알아 먹을 수 있는 기계 어코드(Machine Code-2진수)로 코드 전체를 변환한 다음 실행을 하는 방식이며, 스크립트 언어(인터프리터)는 한 줄씩 바로 해석하여 실행을 시키는 구조로 , 2진수로된 기계어가 아닌, 인터프리터 방식으로 해석할 수 있는 Byte Code로 변환하여 한 줄씩 바로바로 실행시키는 구조의 방식입니다.
1. 컴파일 언어의 장단점 :
컴파일 언어의 장점은 컴파일 과정에의해 코드 전체가 이미 해석이 된 2진수의 기계어 코드를 실행시키기 때문에, 실행 속도가 매우 빠른 장점을 가지고 있고, 단점으로는 약간의 코드 수정이 필요하더라도, 코드 전체를 다시 컴파일해야 하며, 코드의 크기가 크고 방대할 경우 이런 별도의 컴파일 과정으로 인해 다소 번거롭고 시간 소요가 있는 단점이 있습니다. (컴파일 언어의 종류 : C , C++ , C# , Java ... )
2. 스크립트 언어의 장단점 :
스크립트 언어의 장점은 소스 코드 수정이 빠르고 간단해서 수정이 빈번하게 발생하는 프로젝트에 유리하며, 따라서 개발 시간이 단축되는 장점이 있습니다. 스크립트 언어의 단점으로는 실행속도가 컴파일 방식의 언어에 비해 상대적으로 많이 느리다는 단점이 있습니다. (스크립트 언어의 종류 : Python, Ruby, Perl, PHP, JavaScript )
3. 소스코드 형식 :
C언어나 JAVA와 같은 언어의 경우 중괄호 { } 등으로 코드 블록을 구분하는 포맷을 지니고 있고 중괄호 내에서는 일정한 형식을 지키지 않아도 됩니다. 예를 들어, 들여 쓰기가 문법적으로는 필요하지 않으며, 공백의 개수나 코드 길이가 길 경우 별다른 형식 없이 다음 줄로 내려쓸 수 있는 구조를 가지고 있습니다.
Python과 같은 경우는 들여쓰기나 공백의 사용에 주의가 필요합니다.
4. 파이썬(Python) 코드의 작성 구조 및 형식
① 대소문자를 구분해야 합니다. 예를 들어, 변수명으로 'NUM' 과 'Num'과 'num'은 각각 다른 변수입니다. ② 명령어(내장 함수)는 일반적으로 모두 소문자입니다. 예를 들어, >>> print(2+3) ⟵ (맞음) >>> Print(2+3) ⟵ (에러) >>> PRINT(2+3) ⟵ (에러)
파이썬에서는 if 문장이나 for문장의 경우 하위 문장들을 중괄호 { } 등으로 구분 짓지 않기 때문에, 들여 쓰기(Indent)로 구분합니다. 일반적으로는 4칸의 공백을 권장합니다. ③ 인터프리터 언어의 특성상 한 줄씩 코드 구조가 해석이 되어야 하기 때문에, if 문장이나 for 문장의 경우 문장 끝에 ' : ' 콜론으로 마쳐서 표시하게 되며, ' : ' 콜론 표시 이후 들여 쓰기 된 문장들은 모두 해당 if나 for 문장에 포함된 내용으로 인식 및 처리하게 됩니다. >>>if num > 15 : ⟵ ' : ' 을 표시하여 if 문장의 시작을 알림 >>> print("=====") ⟵ 공백을 주어 if 문에 속해 있는 문장으로 처리함 >>> print(num) ⟵ 공백을 주어 if 문에 속해 있는 문장으로 처리함 >>>print("감사합니다") ⟵ if 문에 속해 있지 않은 문장
④ 들여쓰기해야 하는 문장이 아닌 경우는 맨 앞에 공백이 들어가서는 안 됩니다.
>>>1+2↵ >>>3 ⟵ 정상 실행
>>>▒1+2↵ ⟵ 맨 앞에 공백이 들어간 경우 SyntaxError : unexpected indent ⟵ 실행 에러
⑤ 코드 주석은 '#'으로 표시합니다. (다만, 아쉽게도 파이썬은 여러 줄 묶음 주석은 지원하지 않음) ### 파이썬 실습 1번 for i in range(5) : # 0~5 까지 반복 실행합니다. print( "num =" , i )
>>> num=0 >>> num=1 >>> num=2 >>> num=3 >>> num=4
⑥ 위의 예제에서 처럼 파이썬 쉘(Shell) 실행 모드에서 작성하고 있던 for 문이나 if 문에서 벗어나려면 그리고 실행이 되려면 엔터 입력을 두 번 하면 됩니다. for i in range(5) : # 0~5 까지 반복 실행합니다. print( "num =" , i ) ↵ ↵
>>> num=0 >>> num=1 >>> num=2 >>> num=3 >>> num=4
⑦ 파이썬 다운로드 버전? 및 실행시키는 두 가지 모드. 파이썬 다운로드 페이지(python.org)에서 파이썬을 다운로드하고 설치할 수 있습니다. 파이썬은 2000년도에 2.0 버전 발표 이후, 2.x 대 버전과, 3.x 버전의 두 갈래로 나뉘어 발표됩니다. 2.x 대 버전에서부터 비 영어권 언어를 지원하기 시작했지만, 여러가지 문제점과 시스템의 한계로 인해 3.x 대 버전에서는 과거의 시스템을 단절하고 파이썬을 완전히 새롭게 만든 버전을 출시한 건데요, 유니코드를 전면적으로 도입하고 내부적으로 많은 변화가 있어 2.x 대 버전과 호환되지 않습니다. 그런데, 2008년에 3.0 버전을 발표하고 그 뒤에 다시 2010년도에 2.7 버전이 발표 된 이유는, 기존 2.x 버전 베이스로 구축한 시스템에서는 3.x 버전 적용이 되지 않기 때문에, 유지보수 및 업그레이드를 위해 별도로 발표된 것인데요, 그 마저도 더 이상의 버전 업그레이드나 지원이 2020년도에 종료되는 것으로 발표되었습니다. 따라서, 기존 2.x 대 시스템을 다루어야 하는 것이 아니고, 새로 파이썬을 시작하시는 분들은 당연히 3.x 대 버전을 활용하는 것이 좋습니다. 2021년 04월 기준으로 최신 버전은 3.9.4 Version 입니다.
그럼, 파이썬을 다운로드 받아 설치하면 대략 두 가지 형태의 실행 모드를 선택할 수 있는데요, Python Shell(쉘 모드) 모드에서 대화형으로 한 줄씩 작성하고 실행하는 형태로 할 수도 있고,
파이썬 쉘(Shell) 모드에서 대화형으로 코드 작성
메모장과 같은 문서 작성 페이지를 열고"test.py" 형태로 파일을 저장하고 실행 시키는 형태로 작성할 수 있습니다.
파이썬 IDLE를 실행시키고 File 》 New 메뉴로 새파일 작성 후 실행한 모습
위 이미지에서 보듯 파이썬 IDLE를 실행시키고 File 》 New 메뉴로 새 파일 작성 후 실행(F5)하면, 결과 값은 뒤에 있는 Shell 창을 통해 나타납니다.
⑧ print 명령
대화식 모드에서는 print 명령을 사용하지 않더라도 수식이나 변수를 입력하면 출력문으로 해석하여 그 값을 출력해 줍니다. ( 아래 예시, 'print ( x )'로 출력하는 것이 기본이지만, x를 입력 후 엔터 하여도 x 값이 출력됨)
print ( ) 함수의 기본 원형 : print (출력 내용 [, sep=구분자] [, end=끝 문자] ) [ ] 괄호의 내용은 생략 가능하며 필요할 경우 입력합니다.
아래 이미지의 print ( ) 문의 옵션 출력에 대한 예시를 참고하세요.
⑨ 명령어 (내장 함수) 속 수식 계산이나 문자열 출력이 상당히 자유롭습니다. >>> print (2+3+(2*3)-5) ↵
6
>>> print ("고양이 " * 3)↵
고양이 고양이 고양이
이런 방식은 아래처럼 유용하게 응용할 수 있습니다. 보통 화면 출력 시 구분선으로 '---------------------' 같은 것을 여러 개 출력하려 할 때 응용하면 편리합니다.
⑩ 입력 : 입력은 아래와 같은 형태를 취합니다.
변수 = input(' 질문 내용 ')
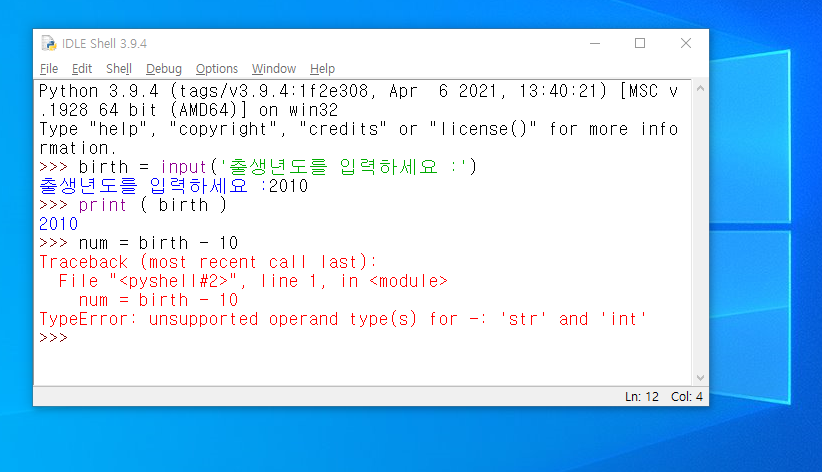
아래 이미지의 입력법 예시를 참조하세요
다만, 현재와 같은 입력은 '2010'이라는 값이 문자로 처리되기에 아래와 같은 산술 계산 시 에러가 발생합니다.
따라서, 이런 경우에는 eval( ..... )이라는 내장 함수를 사용하여 결과 값을 int 형으로 바꾸어 줄 수 있습니다.
다만, eval ( ) 함수는 함수 자체의 막강한 변환 기능으로 인해 코드 구조가 복잡한 곳에 사용하게 되면, 의도하지 않은 값을 변환받을 가능성이 있어, 단순 코드 외에는 사용을 권하지는 않습니다. 따라서, 보통의 경우 int( ) 변환 함수를 사용하는 것을 권합니다.
마지막으로 print ( ) 함수와 input ( ) 함수를 결합하여 아래와 같은 형태로도 활용 가능합니다.
⑪ 키워드 (Keyword)와 변수명 : 키워드는 if , for , while과 같은 단어로, 내장 함수 이름과 같은 예약어를 의미합니다. 따라서 키워드에 해당하는 이름으로는 변수명으로 만들어서는 안 됩니다. 즉, print와 같은 내장 함수를 변수명으로 사용할 수는 있지만 일단 사용하는 순간 이후부터는 print를 출력 함수로 사용할 수 없게 됩니다. 예시)
《 키워드 》
분 류
키워드(Keyword)
제어문
if else elif for while break continue
상 수
True False None
논리 연산자
and or not in
함 수
def return lambda nonlocal global
예외 처리
try except finally raise
모 듈
import from class
기 타
is del with as yield assert pass
※ 변수명 지정 원칙 : - 변수명은 대소문자를 구분하며 소문자로 작성하는 것을 권합니다. ( num , Num , NUM 은 모두 다른 변수명으로 처리됨) - 변수명에는 알파벳, 밑줄 문자, 숫자로 구성할 수 있으며, 공백이나 +, - 나 : / 같은 특수기호 등은 사용할 수 없습니다 (두 단어를 하나의 변수로 만들 경우에는 보통 예를 들어, 'year_data' 혹은 'YearData'와 같은 형태로 작성하면 됩니다.) - 변수명에 첫 글자로 숫자는 쓸 수 없습니다. 'run2you' , 'start100'과 같은 형태는 가능합니다. - 파이썬은 유니코드를 지원하기 때문에, 한글이나 한자와 같은 문자도 변수명으로 사용 가능합니다.
다만, 협업 작업 등에서의 호환성을 위해 일반적으로는 짧고 간결한 영어 표기를 권합니다.
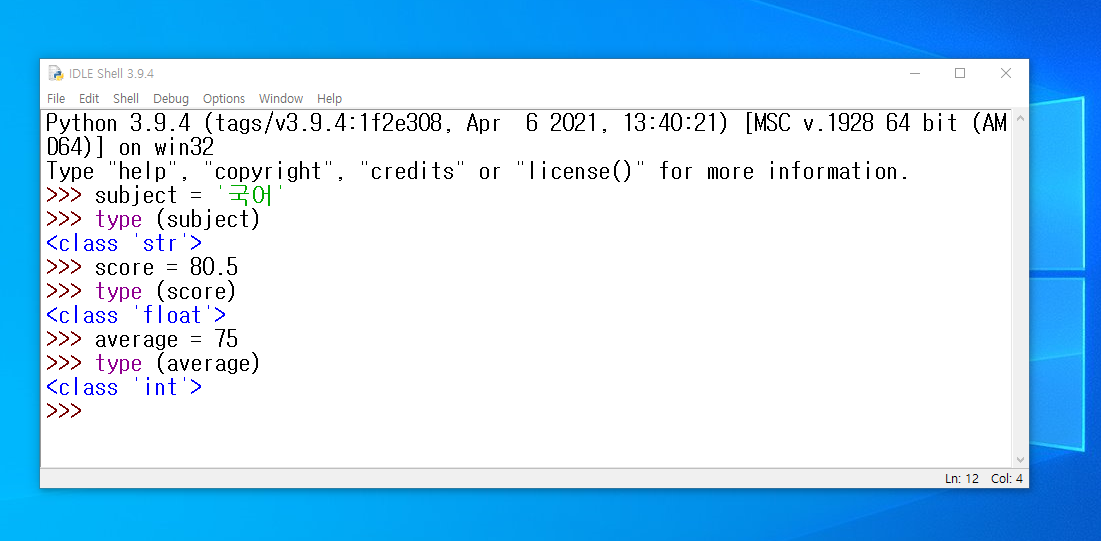
- 파이썬의 변수는 정수형, 실수형, 문자열형 등과 같은 변수의 타입을 사전에 지정하지 않아도 됩니다. 변수에 어떤 값이 저장되는지에 따라 타입이 결정됩니다.
또한, 아래 예시처럼, 특정 타입으로 이미 지정된 변수 명도, 다른 타입의 자료가 입력되면 변수의 타입이 바뀝니다.
이런 파이썬 변수의 특성을 동적 타입 (Dynamic Type)이라고 합니다.
끝으로 하나의 코드에 사용된 변수명을 코드 내에서 삭제할 수 있습니다. ( 다만, 프로그램이 종료되면 어차피 메모리에서 삭제됨으로 자주 활용되지는 않습니다)
- 변수에 초기값 입력시 한꺼번에 (순차적으로) 입력하는 것도 가능합니다. 예) 아래는 변수 초기값 지정시 기본 스타일 >>> name = "Rasino" >>> age = 21 >>> attractive = True
하지만 아래처럼 간편하게 한 번에 대입시키는 것도 가능합니다. >>> name , age, attractive = "Rasino" , 21 , True
또한, 변수명이 각각 달라도 (초기)값이 같을 때는 아래처럼 지정할 수도 있습니다. >>> kimbob = mandu = odeng = noodle = 5
⑫ 파이썬의 주요 자료형
자료형
설명
예시
정수
소수가 없는 숫자
ex) a = 5 , b = 10
부동소수
소수가 있는 숫자
ex) a = 3.5 , b = 3.14169
불 (Bool (불)
True 또는 False 값을 가진 자료형
ex) a = True , b = False
문자열(String)
문자 데이터를 순서대로 나열한 데이터
ex) a ='Rasino' , >>> print(a[0]) → R
리스트(List)
숫자나 문자열 등의 요소를 순서대로 나열한 구조체 (추가 / 삭제 가능)
ex) a = [ 'R','a','s','i','n','o' ] , >>> print(a[3]) → i
튜플(Tuple)
리스트와 비슷하나, 초기값이 정해지면, (데이터 추가 / 삭제가 불가함)
ex) a = ('R','a','s','i','n','o' ) , >>> print(a[4]) → n
딕셔너리(Dictionary)
각 데이터 마다, 이름(Key)이 있는 데이터 모음. 연관성 있는 데이터들의 묶음으로 사용하기 좋음 {'key' : 'Value' , 'key' : 'Value' , ... }
1) 문자열 특징 : - 문자열은 큰따옴표 "...." , 단 따옴표 '....' 모두 가능하며, "....' 섞어 쓰면 에러 발생합니다. - 코드 작성 시 문자열 길이가 길 경우, 임의로 두 줄 이상 내려쓸 수 없습니다. ( 문자열 두 줄 이상 표기 에러 x) stringA = "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세..."
( 문자열 두 줄 이상 표기 올바른 방법 #1 ) stringB ="동해물과 백두산이 마르고 닳도록 ∖ 하느님이 보우하사 우리나라 만세 ∖ 무궁화 삼천리 화려강산..." ' ∖'(역슬래시) 표시는 한글 자판에서는 '\'로 표시됩니다. 역슬래시는 문자열뿐 아니라, 일반적인 수식이나 다른 코드의 작성 시에도 적용 가능합니다.
한 줄 내려쓰기 역슬래시(\) 표기 방법
( 문자열 두 줄 이상 표기 올바른 방법 #2 ) stringB = ''' 동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라 만세 무궁화 삼천리 화려강산... ''' 단 따옴표 3개를 앞뒤로 묶어주거나, """ .... """ 큰따옴표 3개를 앞뒤로 묶어주면 됩니다.
- 스트링 머지 기능 (stringmerge) : 하나의 변수에 콤마로 구분되지 않은 문자열 묶음을 입력하면 합쳐집니다. ex1) >>> A = "Korea" " Fighting" "2021" >>> print ( A ) KoreaFighting2021
ex2) >>> B = ( "Korea" " Fighting" "2021" ) >>> print ( B ) KoreaFighting2021
( 정수를 문자열로 변환 ) 문자 "2021"을 정수로 바꿀 때는 int(2021)라고 설명을 드렸는데요, 반대로 정수를 문자열로 바꾸는 함수는 str(2021)를 사용하면 됩니다. ex1) >>> A = "Korea" + str(2021) >>> print (A) Korea2021
※ 주의 사항 : 하나의 print( ) 함수 내에서는 문자열로만 출력하든지 int type과 같은 숫자 형태로만 구성 되어야 합니다. 즉, print("문자열..." + 정수 ) 와 같은 조합시 문법에러가 납니다. 따라서 이럴때는 문자열 캐스팅 연산자('str( )')를 사용하여 문자열로 통일시켜 주면 됩니다. ex1)
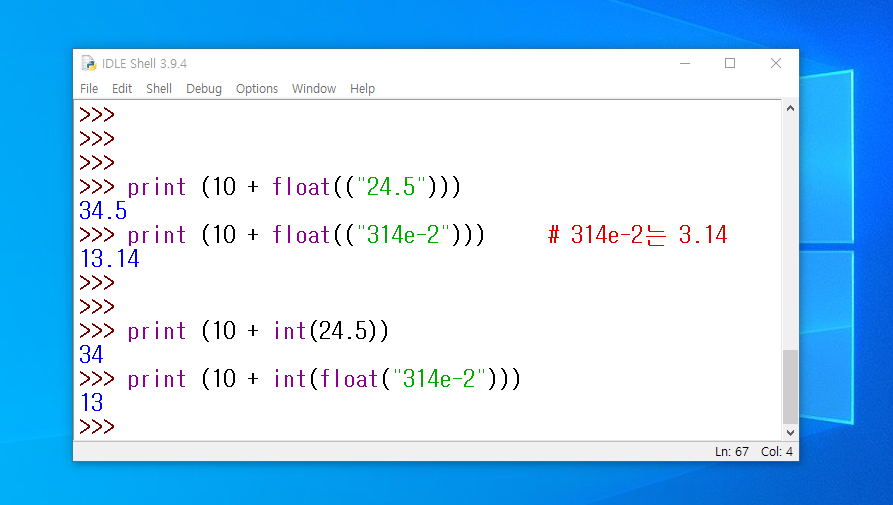
( 문자열 실수를 숫자 실수로 변환 ) int( ) 함수는 문자열 실수 숫자를 소수점 이하를 버리고 숫자로 변환하기 때문에, float ( ) 함수를 사용해야 합니다. 그리고 (실수를 정수로 변환) 하는 방법도 아래 이미지를 참고해 주세요.
(반올림 함수 사용하기 ) 위 이미지에서 보듯 실수를 단순하게 int( ) 함수를 사용하여 변환할 경우 소수점 이하는 버려지게 되는데요, 소수점 이하 반올림이 필요하게 될 경우 round ( ) 함수를 사용합니다.
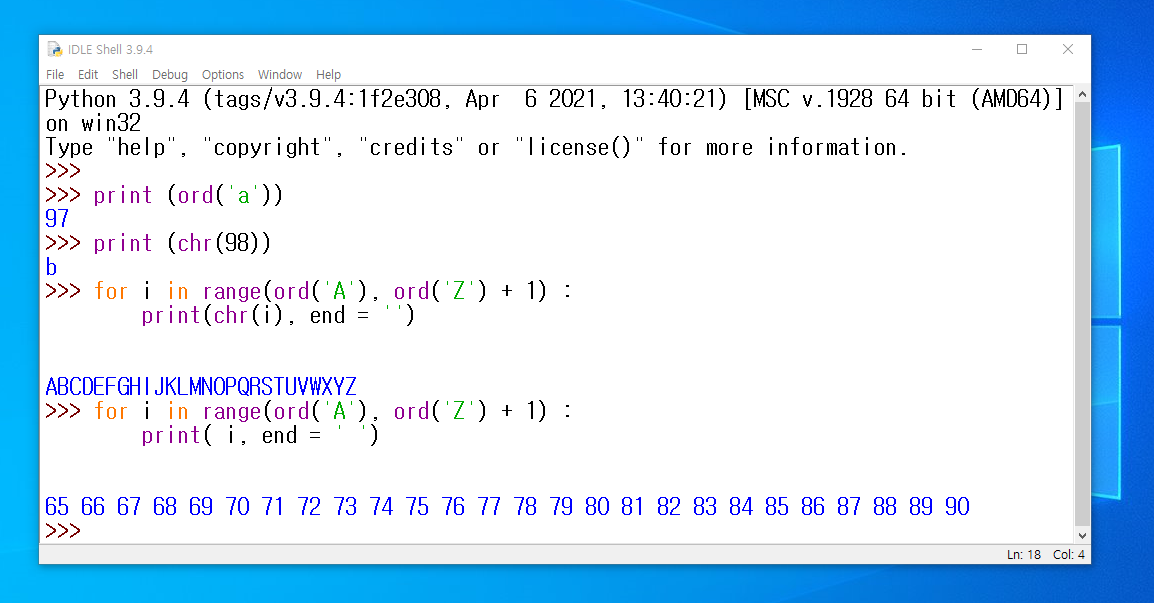
( 문자 코드 확인 함수 ) - 문자 코드 확인 함수 ord( )와 chr( ) 함수 : ord 함수는 아스키(ASCII) 문자뿐 아니라, 한글이나 한자와 같은 문자 변환 시에도 유니코드 값을 출력해 줍니다. ( 3.x 버전부터 파이썬은 대부분의 유니코드 처리 가능한 언어이기 때문 )
2) 리스트(list) 특징 : - 리스트는 구조체의 특징을 가지고 있기 때문에, 정수나 실수 , 문자열 등을 [ ] 대괄호로 묶어 하나의 변수에 담아 놓을 수 있습니다. ex) >>> A = [ 1 , 2, 3, 4, 5] >>> B = [ 'a', 'b', 'abc', 'kt' ] >>> C= [ 'a', 'b', 1 , 2, 3, 'abc', '12kt' ] - 리스트형은 배열의 특성도 지니고 있기 때문에, 특정 순서의 항목을 꺼내거나 삭제 추가 변경 등이 가능합니다.
- 리스트형 데이터의 연산(슬라이싱-Slicing 연산) : 리스트형을 대상으로 슬라이싱 연산이 가능한데요, 다음과 같은 자료의 추출이나 편집이 가능합니다. 또한, 슬라이싱으로 값의 수정이나 추가 삭제도 가능합니다.
위 이미지를 보면, 값의 추가는 값을 변경하는 것으로 이해하면 됩니다. (A[2:3]은 3의 값을 3, 4로 바꾸는 것) 즉, A=[1, 2, 4, 5, 6, 7, 8, 9] 일 때, 2와 4 사이에 3을 추가하려고 한다면, 숫자 4를 3과 4로 바꾸는 것으로 이해해야 합니다. 이것이 슬라이싱을 이용한 추가 방법입니다. [2:3] 에 인자로 사용된 2 : 3을 인덱스라 표현합니다. 인덱스의 제일 처음 값인 0을 생략할 수 도 있습니다. 예를 들어 A [1, 2, 4, 5, 6, 7, 8, 9] 일때, [ : 3 ]은 인덱스 값 처음부터 3 앞 까지를 의미 합니다. 즉, [ 0 : 3 ]와 [ : 3 ] 은 같습니다. 또한, [ 4 : ]는 인덱스 값 4부터 끝까지를 의미합니다. 즉, [ 4 : ]와 [ 4 : 10 ] 은 같습니다. 그리고 [ : ]는 리스트 전체를 의미하며, 따라서, 리스트 전체를 다른 것으로 변경할 수도 있습니다.
또한, 아래처럼 슬라이싱의 인덱스 연산으로 리스트 값 전체 삭제도 가능합니다. A [ : ] = [ ]
슬라이싱 인덱스 연산을 통해 데이터를 몇 칸씩 건너뛰며 출력하거나 변경하는 것도 가능합니다. 또한, 인덱스 값 중에서 짝수 번째나 홀수 번째 자료를 출력하는 것도 가능합니다.
A [0:15:2]에서 2는 1칸의 Step 값을 의미하며, 두 칸은 3, 세 칸이면 4로 하면 됩니다.
2) 리스트(list) 와 함수들 : 아래와 같은 기존 함수를 이용해서 리스트 연산 (추가 , 삭제 , 반환 ... 등 )을 수행 할 수 있습니다.
함수명 (s 는 list 이름을 의미)
설 명
s.append( x )
리스트 s의 끝에 x를 추가
s.extend( t )
리스트 s의 끝에 리스트 t의 내용 전부를 추가
s.clear( )
리스트 s의 내용물 전부 삭제
s.insert( i , x )
s[ i ]에 x를 저장(삽입)
s.pop( i )
s[ i ]를 반환 및 삭제
s.remove ( x )
리스트 s에서 제일 앞에 등장하는 x를 하나만 삭제
s.count( x )
리스트 s에 등장하는 x의 개수 반환
s.index( x )
리스트 s에 처음 등장하는 x의 인덱스 값 반환
① append 함수와 extend 함수 : append 와 extend 함수의 차이점은, append 함수는 하나를 추가할 때 사용하고, extend 함수는 특정 리스트 전체를 추가할 때 사용함. (아래 예시 참조)
② insert 함수와 clear 함수 : insert 함수는 특정 위치(인덱스 값)에 추가하고자 하는 값을 추가합니다. 해당 인덱스에 있던 값이 덮어 써지거나, 없어지지 않고 모두 하나씩 뒤로 밀리게 됩니다. (인덱스 값은 0 부터 시작입니다) : clear 함수는 리스트 안에 있던 내용을 모두 삭제함.
③ pop 함수와 remove 함수 : pop 함수는 표시한 인덱스(위치) 값을 삭제합니다. remove 함수는 표시한 값을 list 함수에서 찾아 삭제합니다. pop과 remove의 차이점은 pop함수는 인덱스(위치)를 기준으로 삭제한다는 점이며, remove 함수는 인덱스 기준이 아닌 list 안에 있는 '값'을 기준으로 삭제해 주는 것이 다릅니다. 또한 pop함수는 삭제된 값을 출력해 주는 특징이 있습니다. 만약 리스트에 없는 값을 삭제하려한다면, 에러를 출력합니다.
④ count 함수와 index 함수 : count 함수는 리스트 속에 찾는 값이 총 몇 번 등장하는지 합계하여 알려주며, index 함수는 찾는 값이 처음 등장하는 인덱스(위치)값을 출력해 줍니다.
⑤ len ( ) 함수와 min ( ) , max ( ) 함수 : 리스트 자료에서의 len( ) 함수는 자료에 포함된 전체 갯수를 알려줍니다. min ( ) 함수는 리스트 중에서 제일 작은 수를 알려주고, max ( ) 함수는 제일 큰 수를 알려줍니다.
문자열의 길이를 반환해 주며, min( )은 알파벳 순서상 가장 앞에 있는 문자를 알려줍니다. max( ) 함수는 알파벳 순서상 가장 뒤에 있는 문자를 알려줍니다. 알파벳 순서에서 대문자가 소문자 보다 순서는 앞에 있습니다. 순서상으로 A, B, C, ... X, Y, Z, a, b, c, ... x, y, z 이런 순서로 됩니다. 아래 예시를 참고해 주세요.
⑥ 기타 문자열 관련 함수들 : 파이썬에서는 문자열도 리스트와 마찬가지로 객체(Object)로 인식합니다. 따라서 각각의 객체(문자열)를 컨트롤 할 수 있는 아래와 같은 함수를 사용할 수 있습니다.
함수
사용 예시
str은 변수명
설명
count( )
str.count("xx")
문자열(str)에 xx가 등장하는 횟수 반환한다.
lower( )
str.lower( )
문자열(str)의 내용을 전부 소문자로 반환한다.
upper( )
str.upper( )
문자열(str)의 내용을 전부 대문자로 반환한다.
strip( )
str.strip( )
문자열(str) 앞, 뒤에 위치한 공백을 모두 제거한 문자열 반환
lstrip( )
str.lstrip( )
문자열(str) 앞에(left) 위치한 공백을 모두 제거한 문자열 반환
rstrip( )
str.rstrip( )
문자열(str) 뒤에(right) 위치한 공백을 모두 제거한 문자열 반환
replace( )
str.replace(old, new)
문자열(str)에서 old를 new로 교체하여 반환
split( )
str.split( )
문자열(str)에서 공백등의 기준문자를 가지고 구분 후 리스트 에 담아서 반환
find( ) 또는 rfind ( )
str.find("xx") , str.rfind("xx")
문자열에서 특정 문자"xx"를 찾아 그 위치값(인덱스)을 반환
isdigit ( )
str.isdigit( )
문자열 str이 숫자로만 이뤄져 있으면, True, 아니면 False반환
isalpha( )
str.isalpha( )
문자열 str이 알파벳으로만 이뤄져 있으면, True, 아니면 False반환
startswith( )
str.startswith("aaa")
문자열 str이 "aaa"로 시작하면, True, 아니면 False 반환
endswith( )
str.endswith("bbb")
문자열 str이 "bbb"로 끝나면, True, 아니면 False 반환
1. count ( ) 함수 사용예시 : 문자열 속에 's' 문자의 수를 카운트하여 줌.
2. lower ( ) : 문자열을 모두 소문자로 변환하여 특정 변수에 저장 하거나, 원래의 문자열에 바꾸어 대입시킬 수 있습니다.
3. upper ( ) :문자열을 모두 소문자로 변환하여 특정 변수에 저장 하거나, 원래의 문자열에 바꾸어 대입시킬 수 있습니다.
4. strip ( ) 함수 : 문자열 앞과 뒤에 있는 공백을 제거할 수 있는 함수입니다. (문자열 중간의 공백은 제거하지 않습니다)
5. lstrip ( ) 함수 : 문자열 앞(left)에 있는 공백을 제거할 수 있는 함수입니다.
6. rstrip ( ) 함수 : 문자열 뒤(right)에 있는 공백을 제거할 수 있는 함수입니다. (또한, strip , lstrip, rstrip 함수 모두 아래 예시처럼, 적용된 함수 결과를 원래의 변수에 대입시킬 수 있습니다)
7. replace ( old, new ) 함수 : 문자열에 속한 특정 문장을 다른 문장으로 바꿀수 있는 함수입니다. (예시, replace("e", "a") 라고 할 때, 'e'라는 문자를 모두 'a'라는 문자로 바꾸어 주게 되며, replace("e", "a", 1) 처럼, 만약 옵션에 숫자 1을 넣으면 앞에서부터 순서대로 하나만(숫자만큼) 빠꾸어 줄 수도 있습니다. ) 아래 예시는, 문장속에 "Rasino" 문자열을, "Python" 문자열로 바꾸는 예시입니다.
8. split ( ) 함수 : 문자열에서 ' ' 공백이나 특정 문자를 기준으로 쪼개어 리스트라는 형식으로 담아 줍니다.
9. find ( ) & rfind ( ) 함수 : 문자열에서 특정 문자"xx"를 찾아 그 위치값(인덱스)을 반환합니다. (인덱스 값은 0부터 카운트 합니다) find ( ) 함수는 문장의 처음(좌측)부터 찾기 시작하고, rfind ( )함수는 문장의 뒤(오른쪽)에서 부터 해당 문자"xx"를 검색합니다.
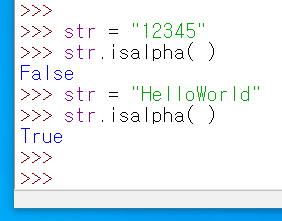
10. isdigit ( ) 함수 : 문자열 함수 str.isdigit( ) 에서 str이 모두 숫자로 이루어져 있을 경우, True를 반환하며, 그렇지 않을 경우 False를 반환.
11. isalpha ( ) 함수 : 문자열 함수 str.isalpha( ) 에서 str이 모두 알파벳으로 이루어져 있을 경우, True를 반환하며, 그렇지 않을 경우 False를 반환. (문장속에 공백이나 특수 문자가 들어 있을 경우, 알파벳이 아니므로, False를 반환 하게 됩니다.)
12. startswith ("aaa") 함수 : 문자열이 "aaa"로 시작하면 True를 반환하며, 그렇지 않을 경우 False를 반환. (예시는 아래 13번 예시와 함께 참조)
13. endswith ("bbb") 함수 : 문자열이 "aaa"로 시작하면 True를 반환하며, 그렇지 않을 경우 False를 반환.
vscode 툴을 사용하다 보면, 라이브러리들이 제대로 import 되지 않을 때가 있다.
예를 들어, import pyautogui 를 철자 틀림 없이 정확히 입력하였으나, pyautogui에 물결 밑줄이 그어지면서,
적용되지 않아 코드를 계속 진행 할 수 없는 상황에 놓이게 된다.
이럴 때는 vscode 설정파일 인 settings.json 을 열어 아래 부분을 수정해주면 된다.
1. vscode 실행 2. Ctrl + Shift + P 3. "Configure Language Specific" 입력, 엔터 4. "Python" 선택 → settings.json 열림 5. python.jediEnabled:false → true 또는 true로 되어 있을 경우 그 반대로 false
설정을 저장하고 나면, vscode 우측하단에, reroad ... 할거냐고 묻는 메세지가 있다 그럼 클릭하여 다시 로드 시킨다. 그러면, vscode 툴이 다시 실행되면서
별문제 없이 import 되는 것을 볼 수 있다.
2. < Ctrl + Shift + P > 단축키를 눌러 아래창을 띄우고 "Configure Language Specific" 입력, 엔터친다
3. < Select Language 대화창에서 → python 을 선택한다. >
4. < settings.json 창이 열리면, 아래해당 되는 부분의 false ↔ true 로 바꾸어 준다 >
그리고 저장 후 리로드 Reroad 후, vscode 재실행 하면 라이브러리가 import 되지 않는 문제는 해결 된다.
【파이썬응용】 파이썬 웹 크롤링#3 (Web Crawling) - 원하는 페이지 수만큼 검색하여 저장하기
크롤링이란, 인터넷에서 특정 검색(어)으로 검색하여 (자료를) 긁어(스크랩) 모우는 행위를 일컫는다. 이를 파이썬 코드나 시스템을 이용해서 반자동으로 긁어 모으고 과정을 일컫는다.
이 번 내용에서는 웹 검색 결과를 스크래핑하여 쉼표 단위로 저장이 되는 csv 형태로 저장하고자 한다.
csv 형태로 저장하는 이유는 메모장에서도 열수 있고, 엑셀에서 군더더기 없이 셀(cell) 별로 읽어 들여, 이후의 가공이나 편집이 용이하기 때문이다.
지난시간에는 네이버 M이라 하여 모바일 버전에서 검색되는 내용을 csv 파일로 저장해 보았다.
이번에는 코드가 조금 더 복잡하지만, 일반 PC 화면에서의 네이버 검색 결과를 저장해보려 한다.
블로그를 기준으로 특정 명령어를 검색하는 것을 기준으로 다루어 보겠다.
필요에 따나, 카페 검색이나, 웹 검색을 원한다면 아래 코드를 살짝만 맞추어 주면 된다.
검색결과는 보통 한 페이지당 10개의 내용(제목과 간단한 설명과 링크)이 담겨 있다. 검색 내용이 많은 경우 이런 페이지가 수십 페이지를 넘어가게 되는데, 직전 크롤링 코드로는 첫 페이지에 나오는 내용만 담을 수 있는 코드여서 2페이지 이상의 내용을 저장할 수 없었다. 그래서 한 페이지에 몰아서 출력되는 네이버 모바일 M의 View 메뉴 검색 페이지를 이용하였던 것이다.
그러나 이번에는, 원하는 검색페이지 수만큼 결과를 저장해 보는 크롤링 코드를 짜 보려 한다.
예를 들아 네이버 검색창에 '파이썬'이라 검색하면, 수십페이지의 검색 결과가 뜨는데, 원하는 페이지 수를 예를 들어 '10'이라고 추가로 입력하면, 1페이지부터 10페이지까지의 검색된 결과 중에서, 타이틀 제목과, 링크 주소를 csv 파일로 저장해 보는 파이썬 코드를 다루고자 한다. (콘솔 창에도 해당 결과를 출력해보자)
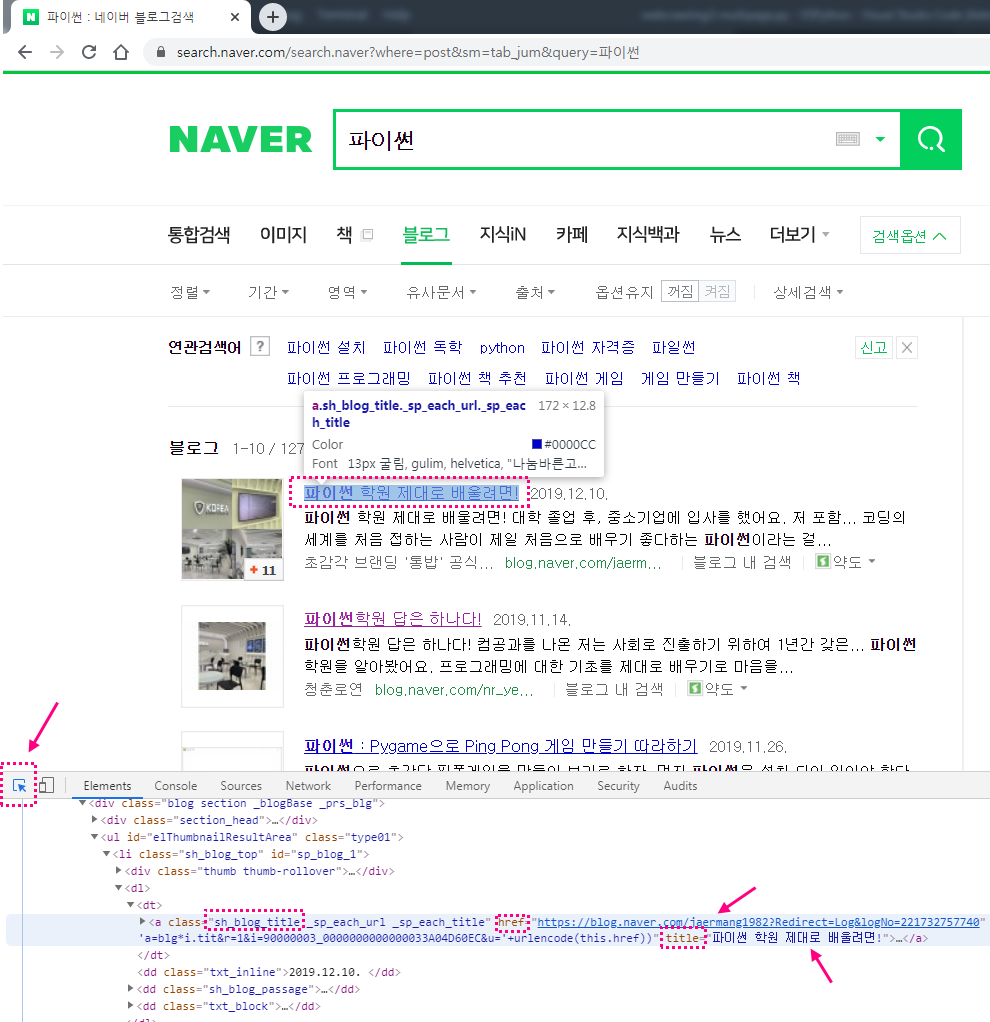
# 먼저 선수학습에 있는 내용을 참고하여, 핵심내용(타이틀 제목과 링크 주소)만 집어 내기 위해, 웹페이지에서 F12키를 눌러 웹 분석도구를 이용해서 'sh_blog_title', title', 'href' 같은 요소들을 파악해 낸다.
그런 다음, 아래코드를 주석을 참고하면서 작성한다.
# 아래 url 주소 부분은 네이버 검색창에서 '파이썬'으로 검색 후 블로그 항목 클릭한 상태에서, 검색 하단에 보면, 검색 페이지들이 숫자로 되어 있는 부분이 있다. 여기 페이지 숫자 아무거나 하나를 클릭한다.
그런 다음 나타나는 웹브라우저의 주소창의 주소를 복사해서 붙여 넣으면 되고, 주황색부분을 보면 기존에 있는 내용은 삭제를 하고 아래처럼 바꾸어 주면 된다.
주소 부분 : https://search.naver.com/search.naver?date_from=&date_option=0&date_to=&dup_remove=1&nso=&post_blogurl=&post_blogurl_without=&query=%ED%8C%8C%EC%9D%B4%EC%8D%AC&sm=tab_pge&srchby=all&st=sim&where=post&start=1
위 주소부분을 카피해보면, 한글 검색의 경우 '파이썬'의 아스키코드 변환 값인 '%ED%8C%8C%EC%9D%B4%EC%8D%AC' 형태로 되어 있는데, 이 부분을 삭제하면 된다.
이 부분을 삭제하고 변수로 입력받아 원하는 검색어로 검색하게 하려는 것이다.
또한 검색하단에 검색 페이지 숫자를 클릭해서 나오는 값은 주소 끝부분에 나타나는데, 이 부분만 페이지를 바꾸어 누를 때마다 달라진다. 어떻게 변하는지 각 페이지를 클릭해보면 파악할 수 있다.
1 페이지 끝 부분 숫자는 '1' 로 되어 있다.2 페이지 끝 부분 숫자는 '11' 로 되어 있다.3 페이지 끝 부분 숫자는 '21' 로 되어 있다.
위의 캡쳐 이미지를 살펴보면, 첫 페이지 끝 부분 숫자는 '1'로 되어 있고, 2페이지 끝 부분 숫자는 '1' 로 되어 있으며, 3 페이지 끝 부분 숫자는 '21' 로 되어 있음을 알 수 있다.
그렇다면, 4페이지는 숫자가 '31', 5페이지는 숫자가 '41'이런 식으로 바뀐다는 것을 짐작할 수 있게 된다.
따라서, 이 숫자 부분을 변수 처리하여 원하는 페이지를 입력받아 해당 페이지까지만 검색결과를 저장하는 코드를 작성해 볼 수 있다.
1. 코드 code
~~~~~~~~~~~~~~~~~~~~~~~~~~~
import csv
import urllib.request
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
search = input('검색어를 입력하세요:')
pageNum = 1
i = input('검색할 페이지 수? :') # 숫자를 입력받아도 input()함수는 문자로 저장된다.
# 블로그 검색 1페이지는 끝에 숫자가 01, 2페이지는 11, 5페이지는 41... 10페이지는 91 붙는다
lastPageNum = int(i) * 10 - 9
f = open(f'{search}.csv', 'w', encoding='utf-8', newline='') # 검색 제목을 입력하면 그 이름으로 파일 오픈(저장)
searchList = []
# 아래 주소 줄에서 주황색 부분, quote_plus() 를 추가하여 search에 한글 제목이 입력될 경우 , 한글제목.csv로 저장되도록 한다 '한글 검색어에 대한 대응(변환)을 위해 quote_plus( ) 함수 사용하여 변환.
# 검색 페이지별로 url이 달라지는 부분은 아래 주황색 부분인 것을 클릭해보면 알아 낼 수 있다.
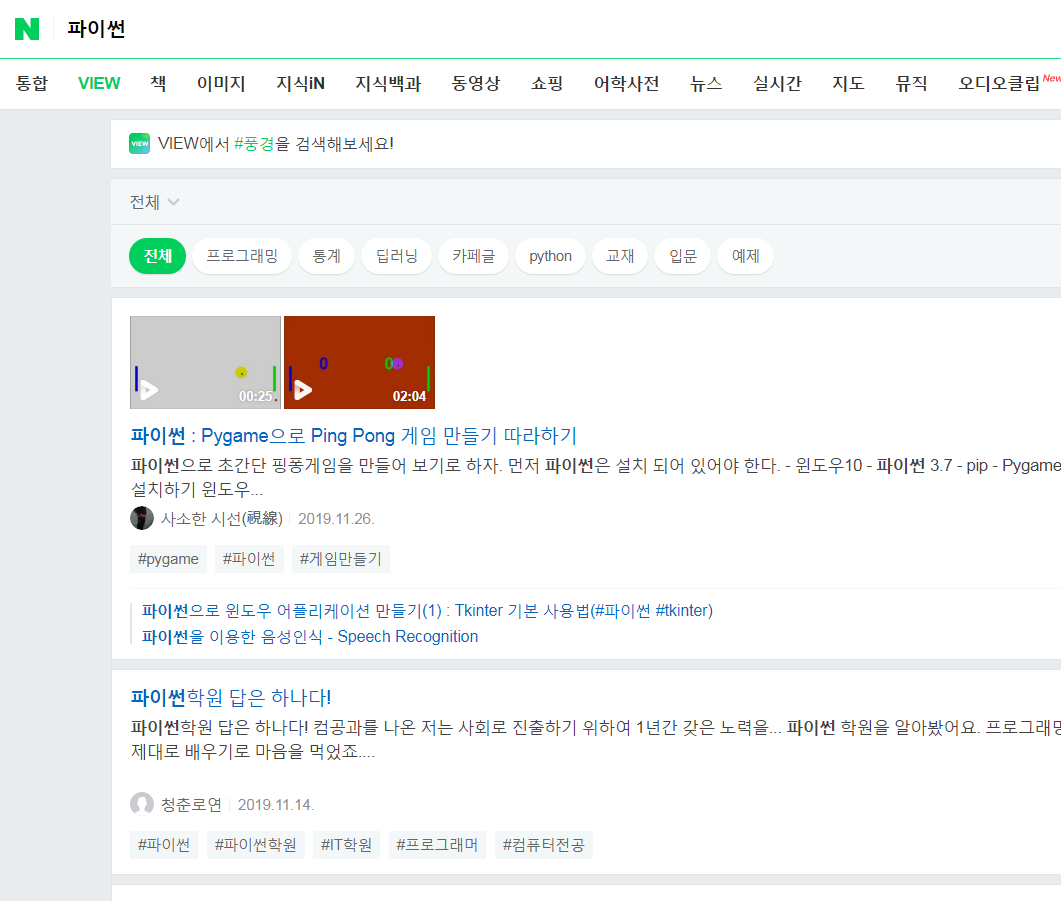
【파이썬응용】 파이썬 웹 크롤링#2(Web Crawling) -검색결과를 csv파일로 저장하기
크롤링이란, 인터넷에서 특정검색(어)로 검색하여 (자료를) 긁어(스크랩) 모우는 행위를 일컫는다. 이를 파이썬코드나 시스템을 이용해서 반자동으로 긁어 모으로 과정을 일컫는다.
이 번 내용에서는 웹 검색 결과를 스크래핑하여 쉼표 단위로 저장이 되는 csv 형태로 저장하고자 한다.
csv 형태로 저장하는 이유는 메모장에서도 열수 있고, 엑셀에서 군더더기 없이 셀(cell)별로 읽어 들여, 이후의 가공이나 편집이 용이하기 때문이다.
이번에는 지난시간과 달리 검색되는 내용을 전체페이지 모두 긁어 저장하려 하는데, PC버전 네이버로 검색하지 않고 모바일 버전인 네이버 M 버전으로 PC에서 검색하는 형태로 코딩을 구성하려 한다.
왜냐하면 모바일 M 네이버의 (VIEW 메뉴 클릭) 하면, 검색 결과를 10개씩 페이지 별로 나타 내지 않고, 한 페이지에 모든 검색 결과를 담아 보여주기 때문인데, 스크롤 내리는 족족 검색되는 결과를 보여주기 때문에, 페이지 단위별 스크래핑을 고려 할 필요가 없기 때문이다.
PC에서 모바일 버전 네이버 검색을 해보려면 m.naver.com 으로 접속을 하면 되며,
검색창에 '파이썬' 검색을 입력하고 검색한 후 메뉴에서 View 를 클릭해서 보면,
검색결과가 계속 내려도 한 페이지에 모두 표시 되도록 스크롤이 계속 내려가는 것을 알 수 있다.
f = open(f'{search}.csv', 'w', encoding='utf-8', newline='')
csvWriter = csv.writer(f)
# 반복문을 만들어 csv 파일에 하나씩 데이터를 추가(기록)해준다.
for i in searchList:
csvWriter.writerow(i)
f.close()
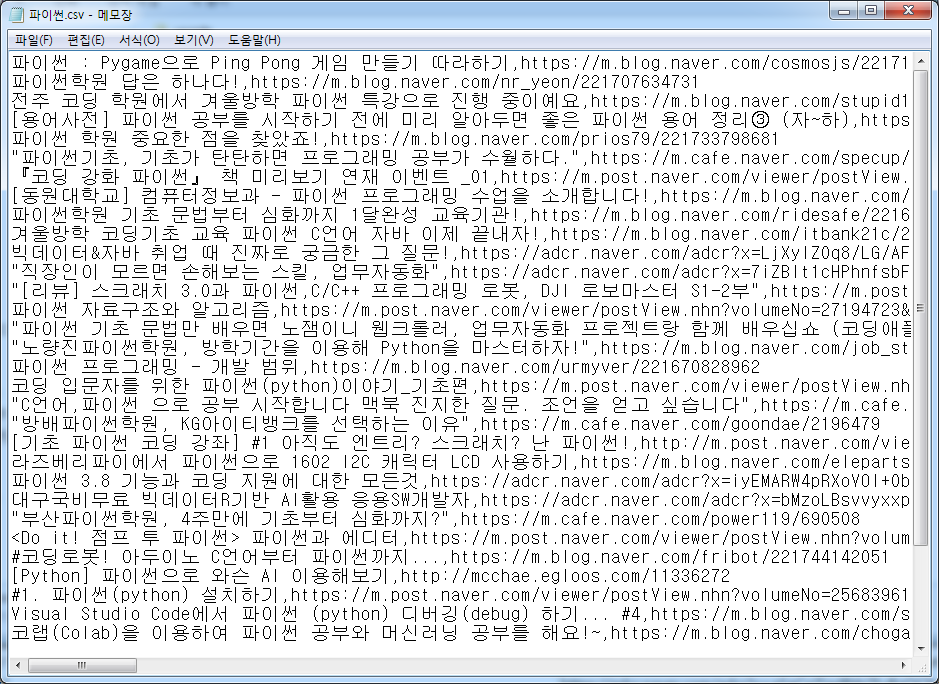
출력 결과 :
아래와 같은 형태의 파일이 저장 되었다.
이 파일을 엑셀과 같은 프로그램으로 열어 보면 저장이 되어 있다. 다만, 아래 처럼 깨져 열리게 된다.
이럴때는 리브레 오피스 같은 걸로 열 경우(유니코드UTF-8) 형식으로 옵션을 맞추어 열면 한글이 깨지지 않게 열린다.
만약 MS엑셀 같은 걸로 열경우는 열기전에 Utf-8로 미리 설정하는 옵션이 없기 때문에,
파이썬.csv 파일을 메모장으로 열고 메모장에서 열면 아래처럼 한글이 깨지지 않게 열리고,
이를 다른이름(파이썬1.csv)으로 저장할 때 '인코딩(E)' 옵션 부분을 눌러 ANSI로 저장한다.
그런 다음 MS엑셀에서 열면 맨 아래 그림처럼 한글이 깨지지 않게 잘 열리게 된다.
※ 컴파일 과정에서 에러가 난다면, url 부분에 공백이 들어가면 안 되니 확인해보면 된다.
여기에서 일반 PC용 네이버 페이지를 이용하지 않고, M.naver 페이지의 View 메뉴를 이용한 이유는 검색어로 검색했을 때 페이지 단위로 검색이 되면 그 한 페이지(약 10개) 정도의 내용만 페이지 별로 분류가 되기 때문에 좀더 복잡한 코드(방법)을 사용해야 하기 때문이다.